From Postgres to ClickHouse: Achieving Real-Time Aggregations with Materialized Views and Cutting Costs by 80%

Overview In the pursuit of real-time analytics at scale, teams often face a key architectural decision: continue scaling traditional…
 Wingify Engineering
Wingify EngineeringOverview In the pursuit of real-time analytics at scale, teams often face a key architectural decision: continue scaling traditional…


Introduction Today, if you’re building a software product for people around the world, you need to support many languages. In this blog, we…

VWO Editor: Seamless DOM Manipulations for React-based Websites VWO Editor empowers users to make "what-you-see-is-what-you-get" (WYSIWYG…
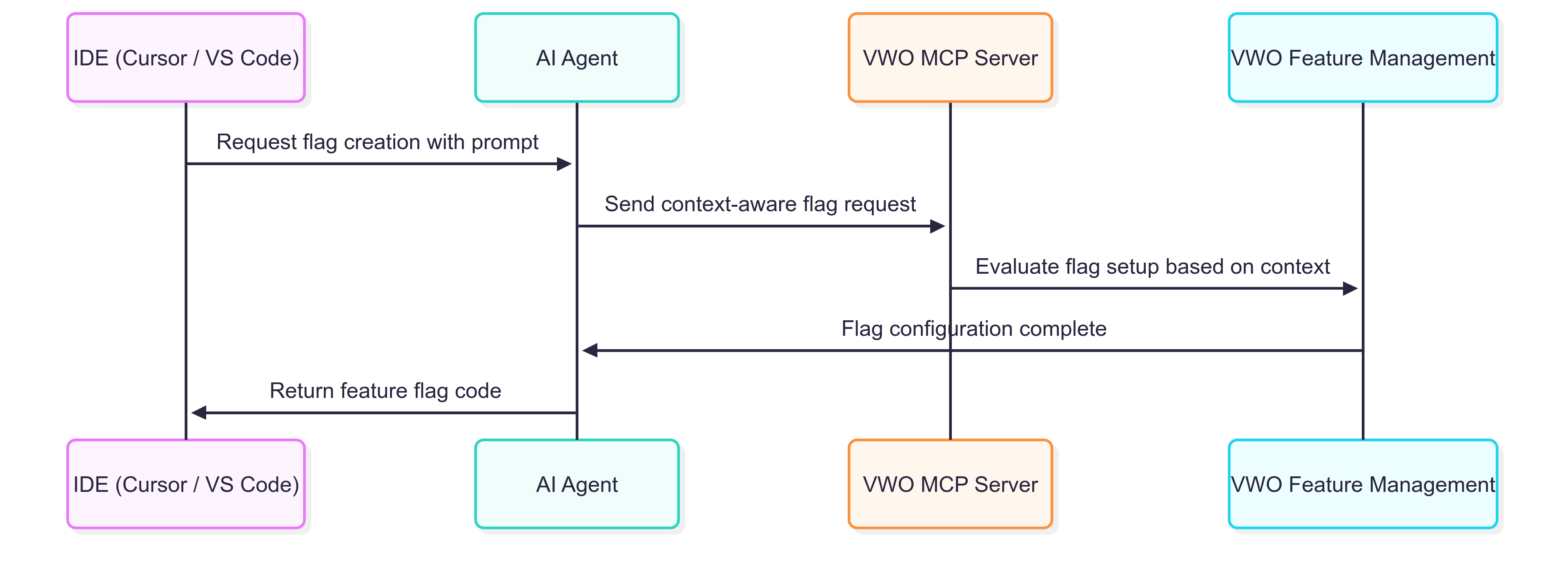

Introduction: Why Feature Flag Management & Experimentation Needs a Revolution In today's world, managing feature flags is an essential part…
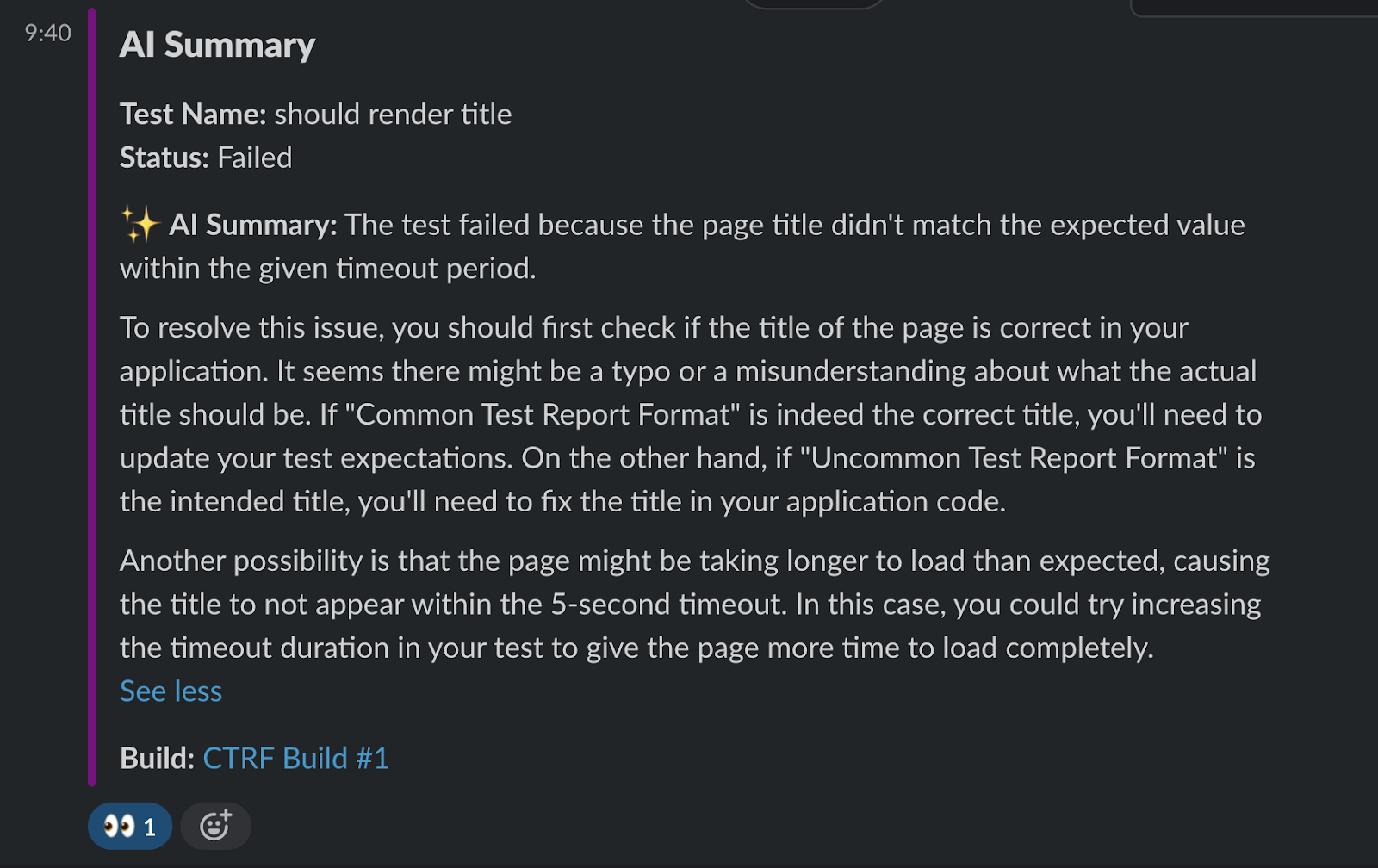

Introduction Wingify dramatically improved its software testing process by integrating the Common Test Report Format (CTRF) with AI-powered…
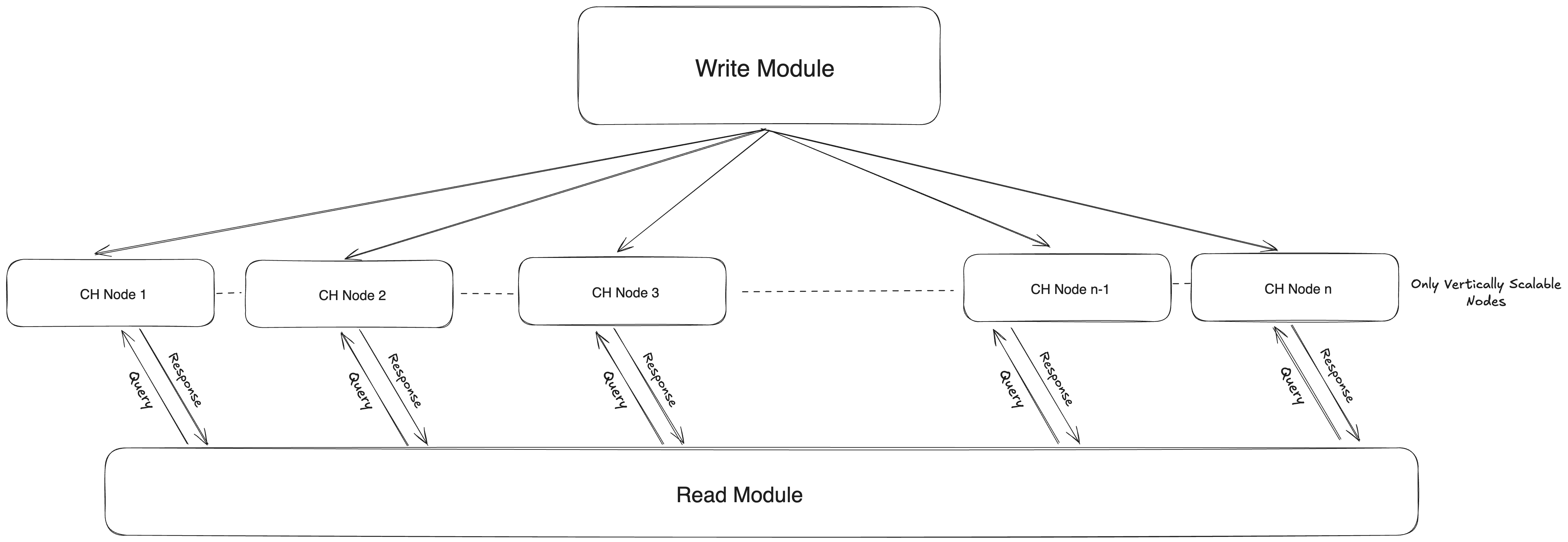
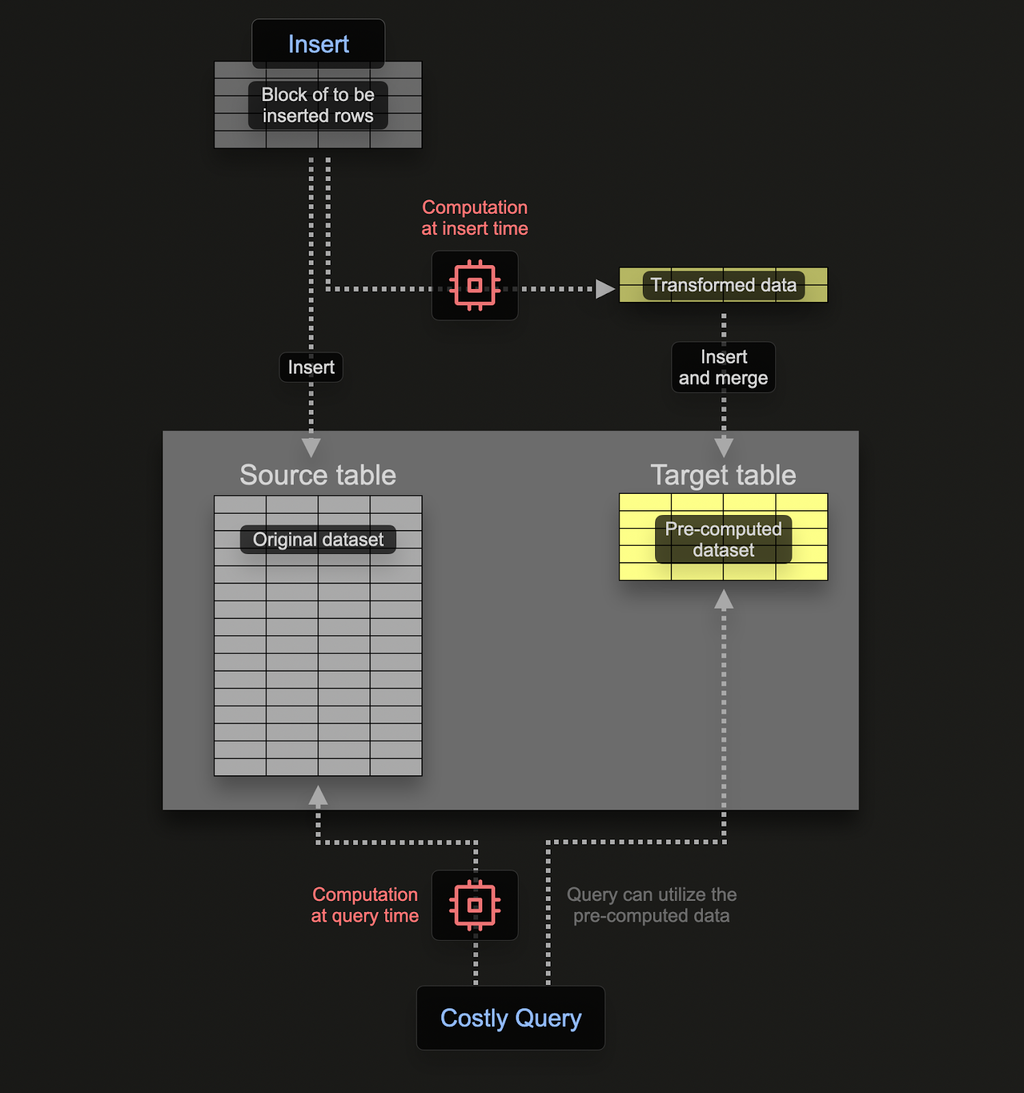
Preface In high-performance data platforms, efficiency and scalability are paramount. ClickHouse, renowned for its blazing-fast analytics…


Preface Writing slick user interfaces has never been so delightful as it is now. You’ve got amazing frameworks, state management patterns…
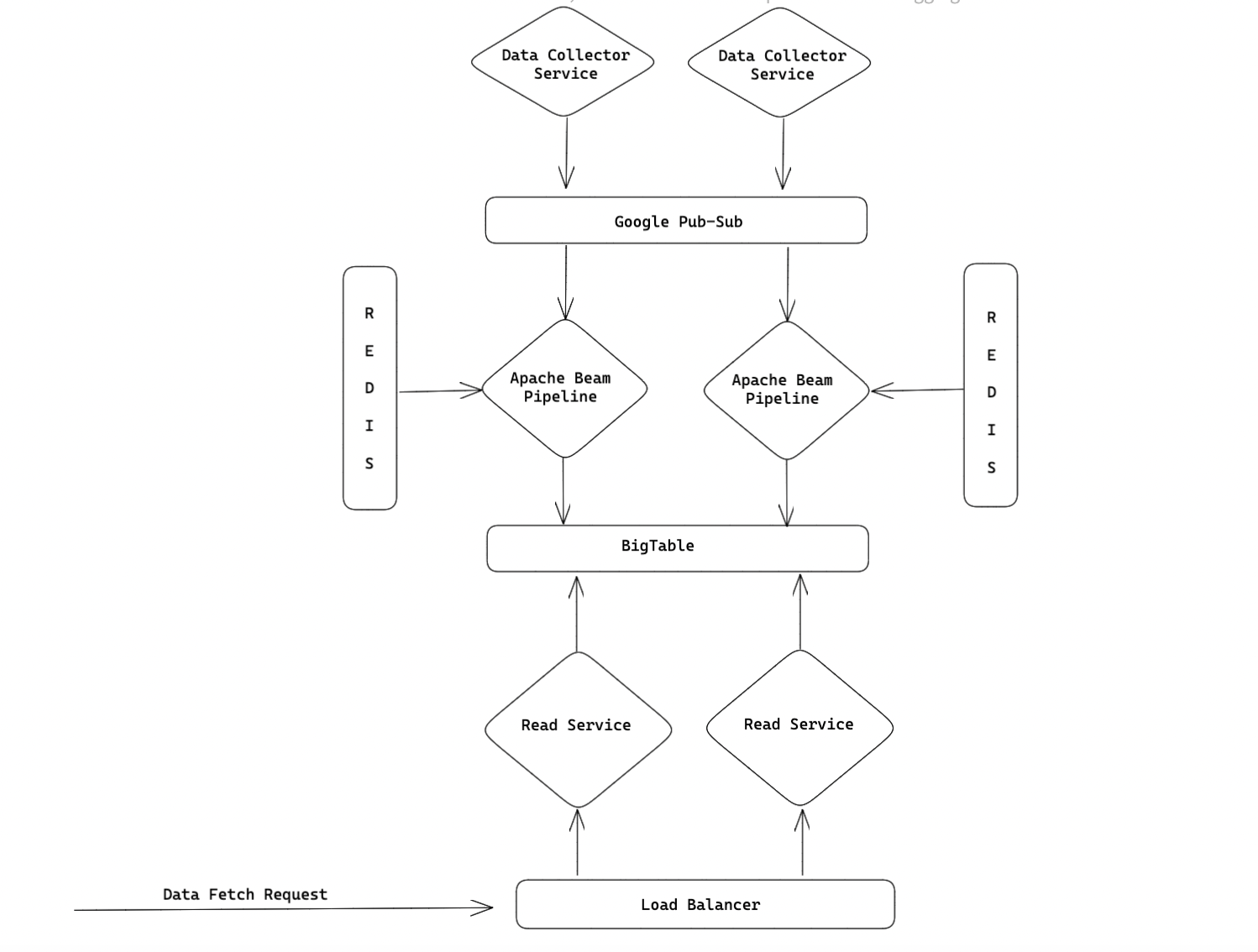

Introduction In VWO, we present clients with information about the data of their users' events in aggregated form on their dashboard…
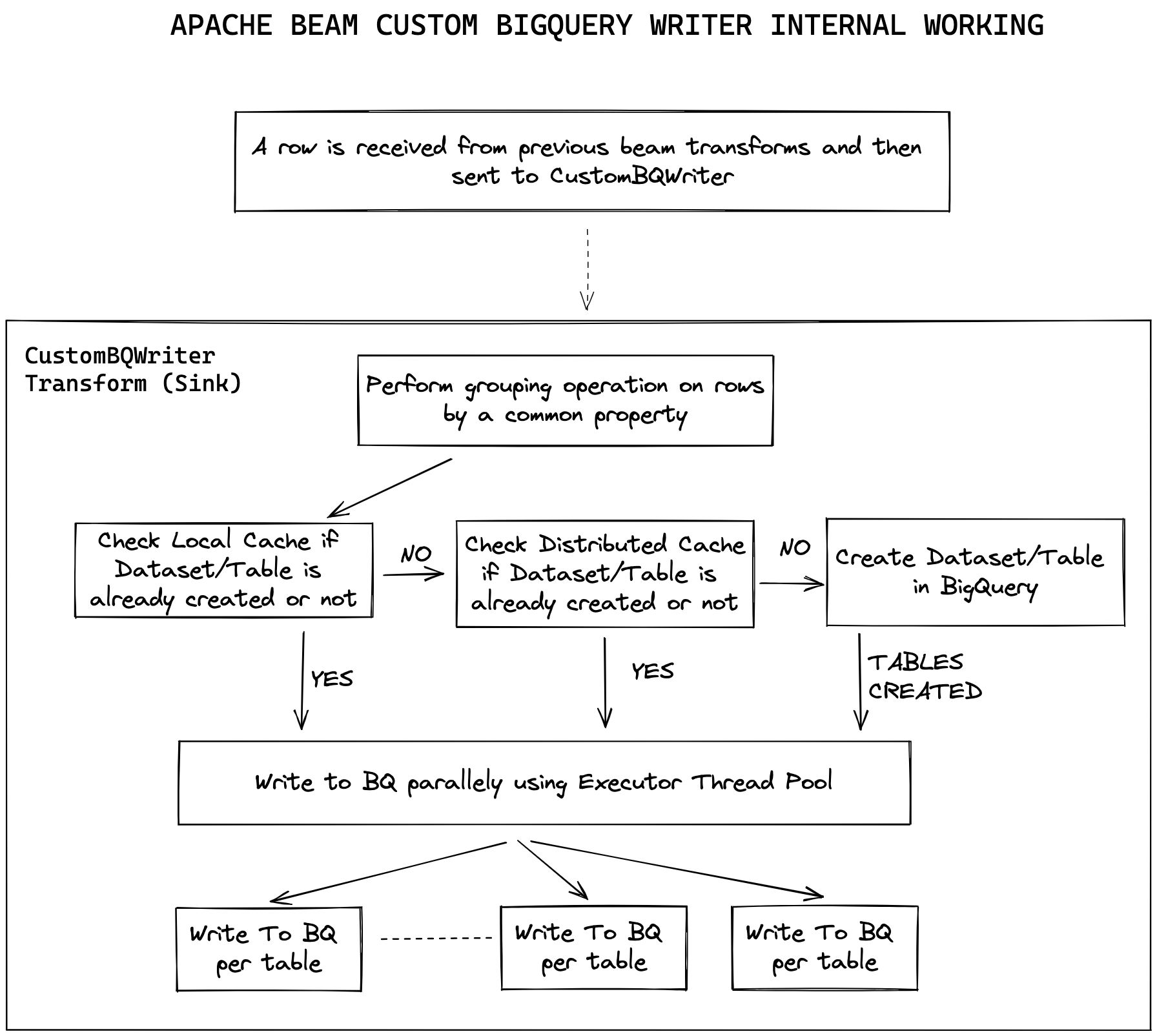
Introduction BigQuery is a completely serverless and cost-effective enterprise data warehouse provided by the Google Cloud Platform. Just…

A Little History Having a functional approach to a problem does not kick off the adventurous journey of learning a new language, instead, it…


The Requirement In VWO, we have our client-side library which is executed on our customer’s website and it is the stepping stone of every…

Client issue assignment and tracking. We at Wingify take our client issues very seriously and have built processes to get the desired…

REST Assured is a Java-based library, one of the most popular libraries to test RESTful Web Services, and is used to perform testing and…

The hunt has ended. Protractor's successor has finally been found! Introducing Playwright, the new star of test automation:-). An end-to-end…
Quality is never an accident. It is always the result of intelligent effort. In line with the above quote, we organized a quality-focused…
We, at Wingify, have implemented our web automation tests using Protractor. Although the old horse has served us well it is fast approaching…
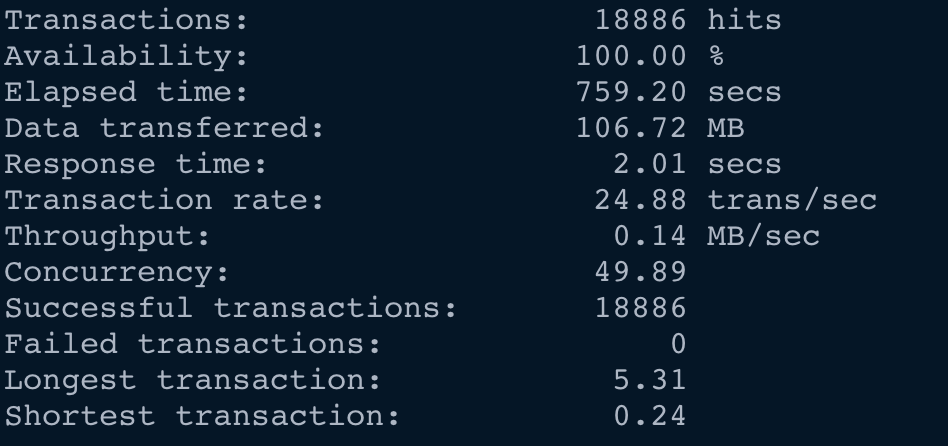

Introduction The search algorithm implemented in your website greatly influences visitor engagement. A decent implementation of a search…

Introduction We are often faced with the problem of source code that breaks frequently. Or those modules which are very sensitive to changes…
Overview Shadow DOM has slowly and steadily become an integral part of modern web apps. Before this, the Web platform provided only one way…
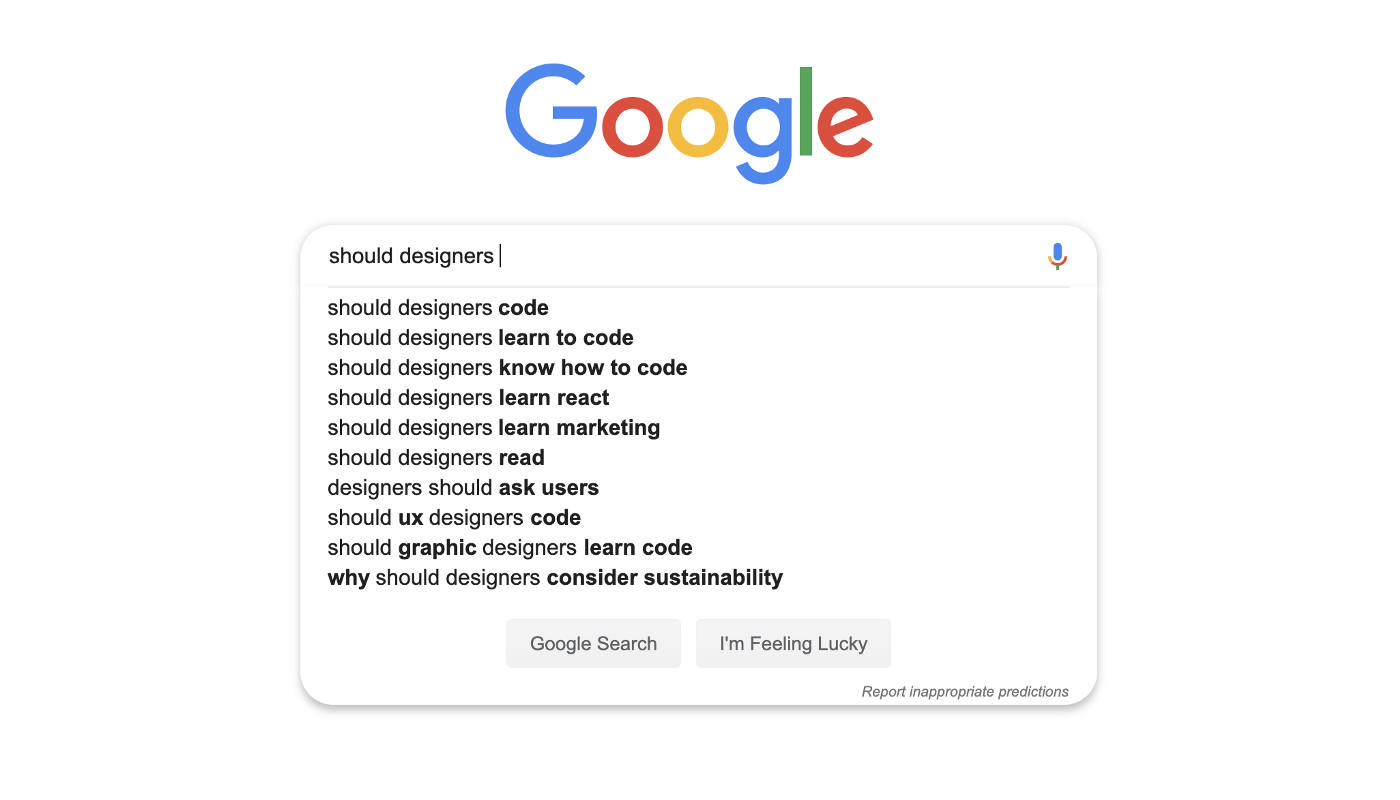

The term designer is used across many domains. In the context of this article, it refers to a UX (User Experience) designer. One question…
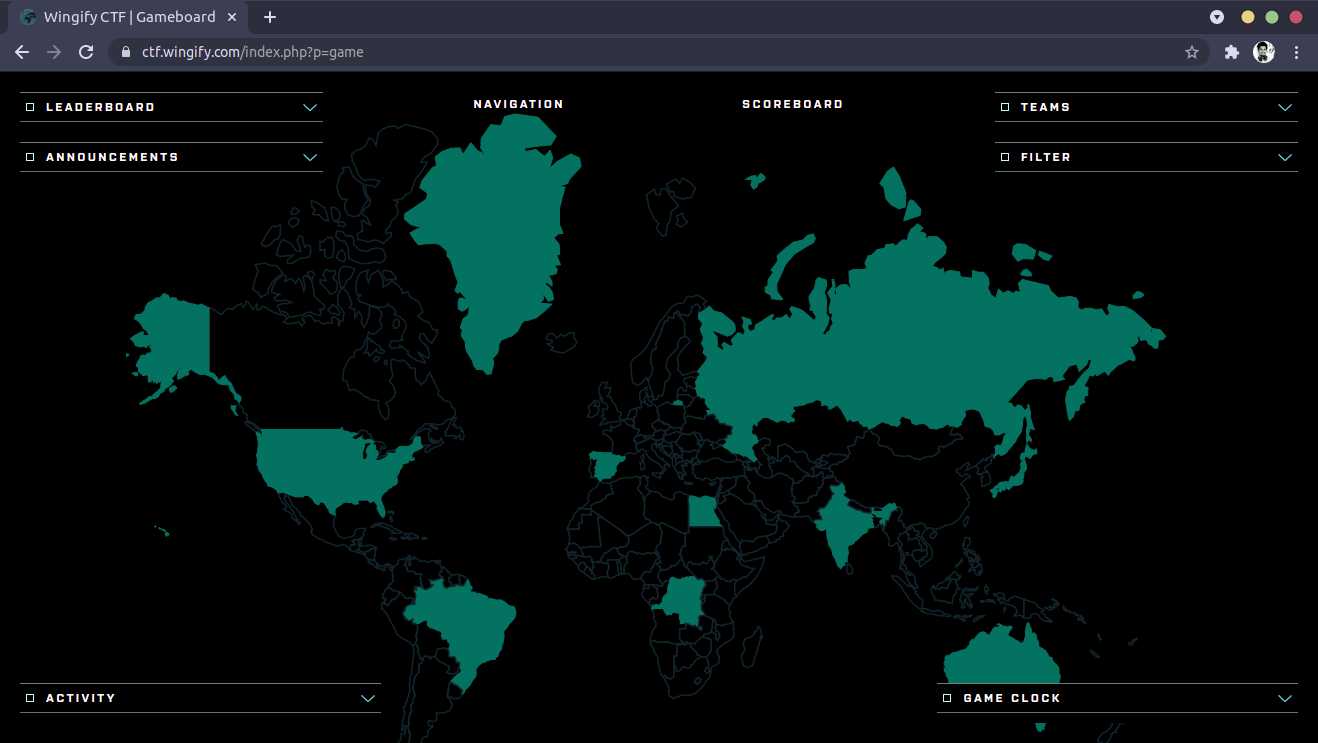

Here at Wingify, we love solving problems and puzzles. To spread this spirit of problem solving, we organized the fourth edition of Capture…

Introduction At VWO, we get traffic at a very high throughput (22K req/sec) to our servers. The data pipeline crunches and transforms the…
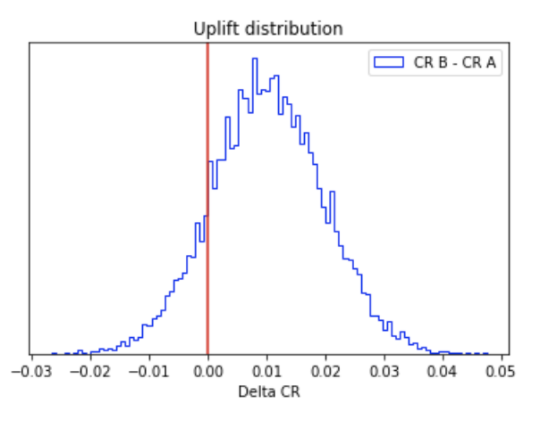

Introduction The culture of experimentation is strongly picking up in several sectors of industry. It has become imperative to measure the…
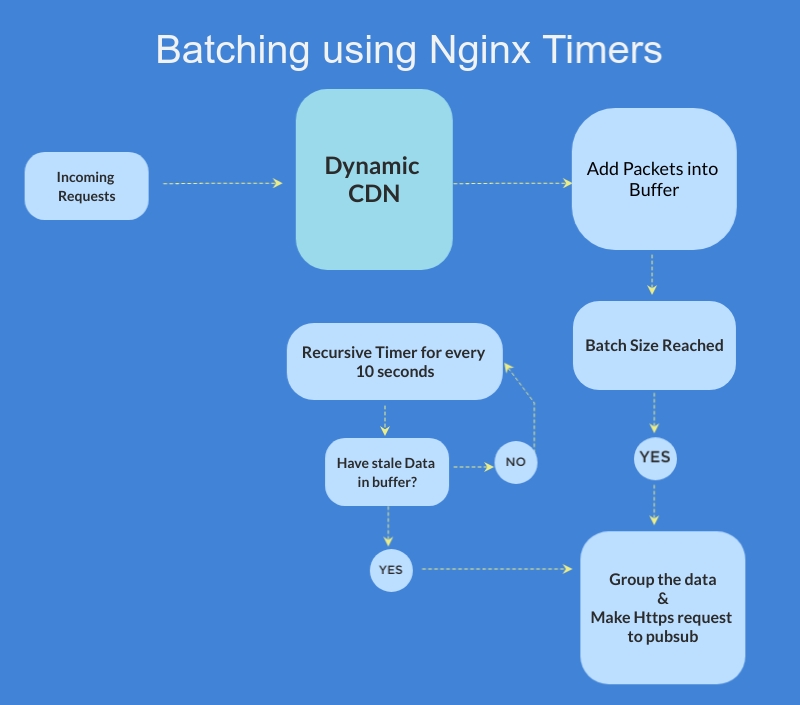
Introduction Lua as a part of the OpenResty package, is extensively used in our in-house Dynamic CDN (DACDN) module. CDN generally is used…
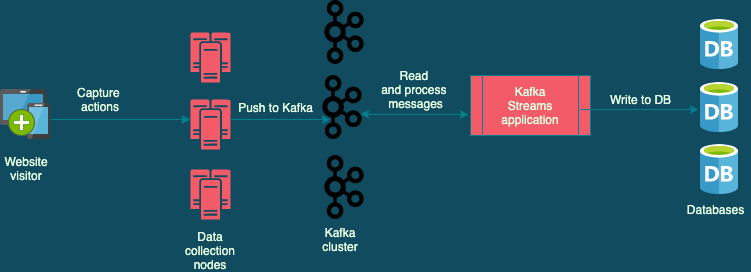

At Wingify, we have used Kafka across teams and projects, solving a vast array of use cases. So, when we had to implement the VWO Session…
Overview We recently started with moving a lot of our infrastructure onto Google Cloud Platform. With this, we also decided that a lot of…


VWO puts a lot of focus on ensuring websites remain performant enough while using VWO. We have been increasing the efforts in this area and…


On March 29th, 2019, our team members Ankit Jain, Dheeraj Joshi and I had the privilege to attend a very exclusive event called BountyCon in…
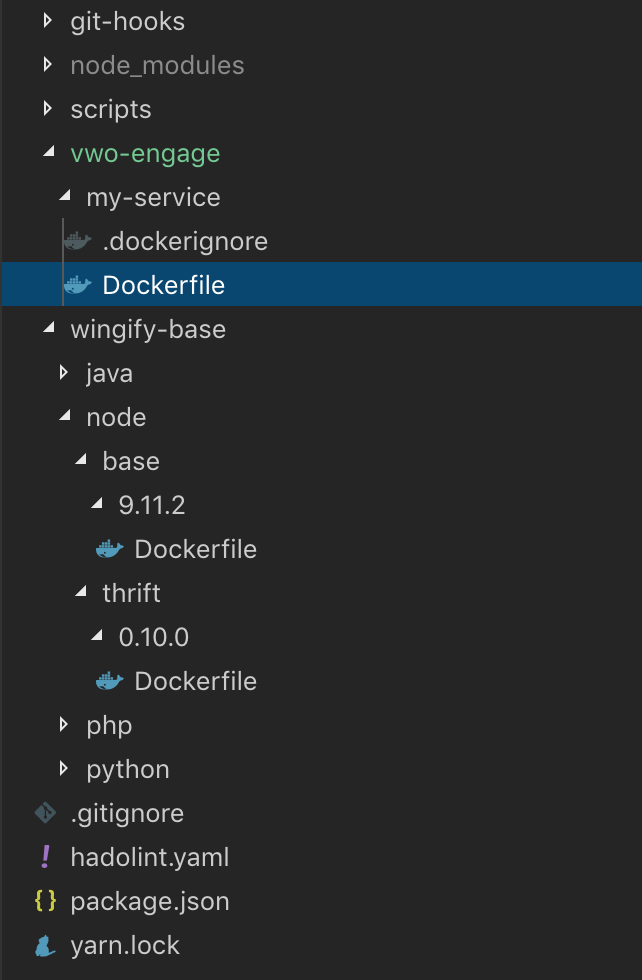

Introduction: At Wingify, we follow microservices based architecture to leverage it's great scalability benefits. We have a lot of…

Introduction: Js13kGames is a JavaScript game development competition that is organized every year from 13th August to 13th September. What…

For the past few months, we at Wingify, have been working on making a common platform for different products - so that things get reused…
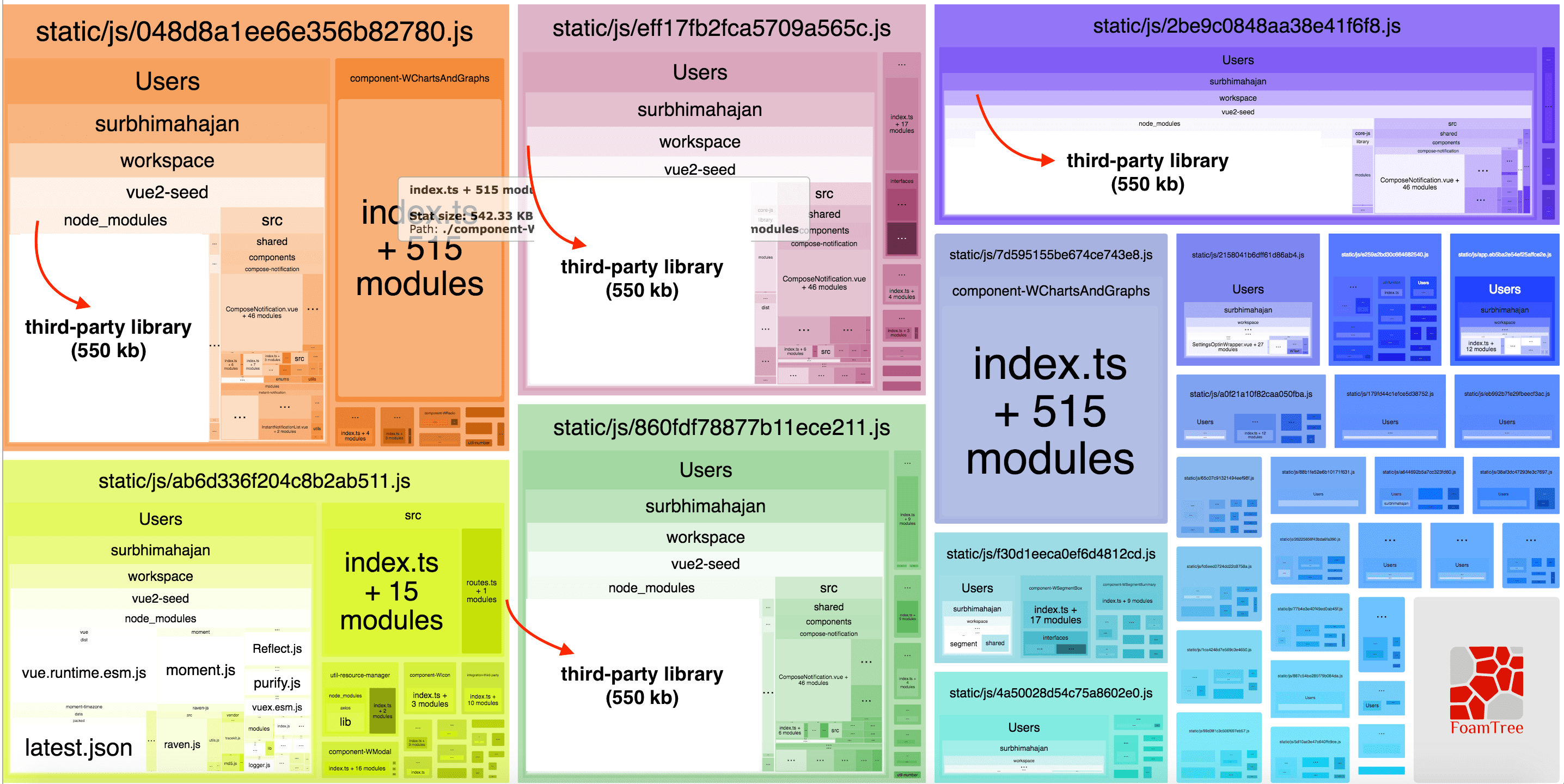

Recently, we migrated one of our web apps to the Webpack 4, which decreases build time and reduces chunk size by using Split Chunks plugin…
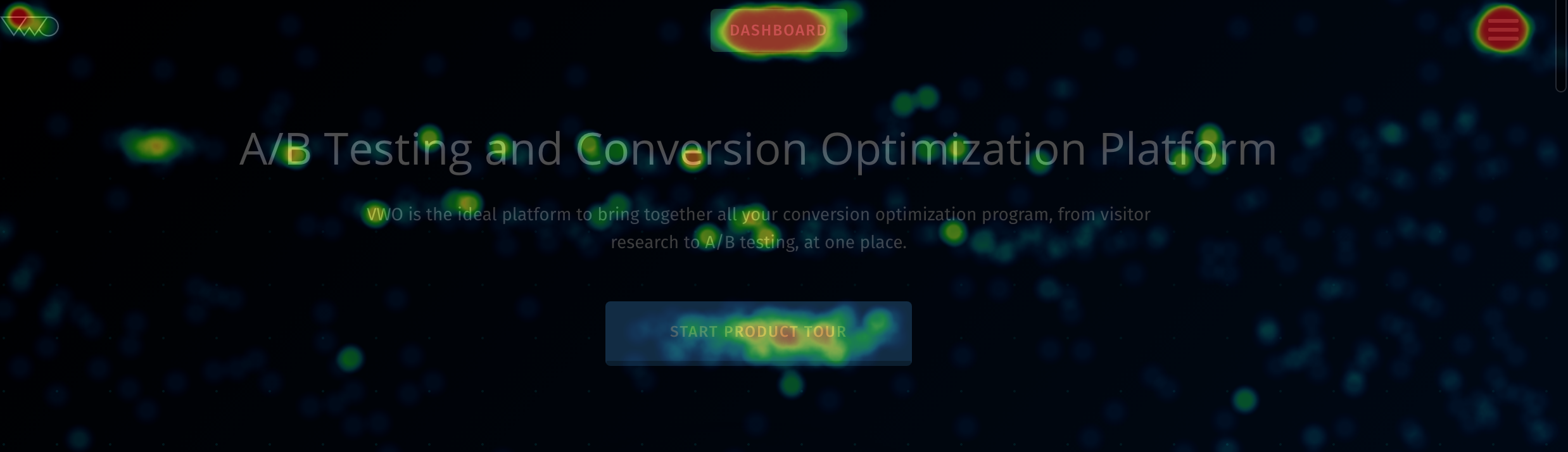
Heatmaps record visitor clicks on the live state of your website, which can be used to interpret user behavior on elements like modal boxes…

This article is inspired from Animating Vue JS by Sarah Drasner at JS Channel 2017. Problem Statement - Why Animation? Website UI…

SASS is a preprocessor that provides features like variables, nesting, mixins, inheritance and other nifty goodies and makes CSS clean and…
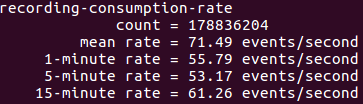

I have been working with Apache Kafka for more than 4 years now and have seen it evolve from a basic distributed commit log service…


For the past couple of years, we have been using require.js for module loading and Grunt for automating tasks on front-end, for one out of…


"What is the most resilient parasite? Bacteria? A virus? An intestinal worm? An idea. Resilient... highly contagious. Once an idea has taken…
Shipping a bug-free feature is always important in every release. To ensure this, we do quality analysis(QA) at various points of the…


About PyData I recently got an opportunity to speak at the PyData, Delhi. PyData is a tech group, with chapters in New Delhi and other…

Introduction This article will deal with the issues we face with the current API architecture (mostly REST) and why demand-driven APIs seem…

Capture the Flag (CTF) is a special kind of information security competition which provides a safe and legal way to try your hand at hacking…


I am a frontend developer at Wingify and I am building a really awesome product, PushCrew. Last month, we had a hackathon. The idea was to…

Recently, Wingify had organised a 24-hour Internal Hackathon where the developers from Wingify created a lot of awesome projects for daily…

Last two months were quite amazing for me as a Wingifighter; I was on a traveling spree over Italy and London. I got an opportunity to…
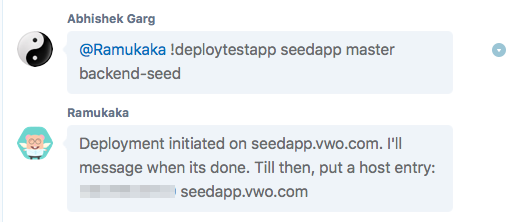
Few days back, we open-sourced our internal Skype bot to the world. Its called Heybot!, but we call it Ramukaka at Wingify :) Whether its…
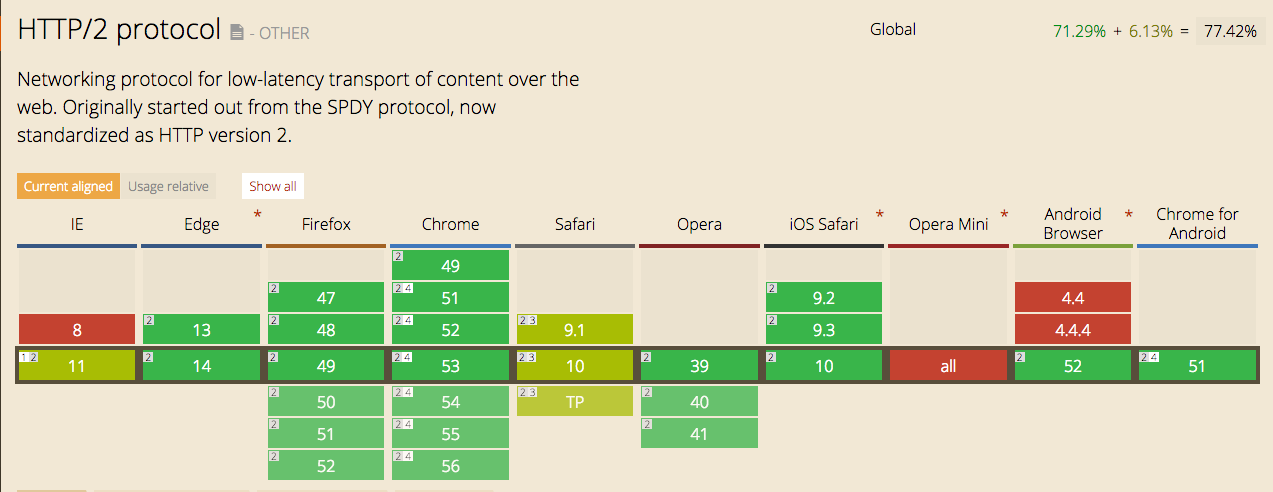
About two years ago, Wingify had introduced the new generation of our Visual Website Optimizer to the world. Boasting a modern visual…

Recently, I spoke about securing Web Applications at JSChannel Conference ’16. The conference venue was The Ritz-Carlton, Bangalore…


There were just two hours left to catch a flight for an exciting opportunity to present at the biggest Selenium conference, SeleniumConf…
At Wingify, we recently began an initiative by the name Engineering Talkies where our engineering teams share their experiences, repertoire…
Coding is always fun at Wingify, be it a Wingify Camp or a Fun Friday. And to add to the fun, in a Fun Friday Code In the Dark was organized…
Few weeks ago, we did a redesign of our product - VWO. It wasn't a complete overhaul from scratch, but some major design decisions were…

In the GOF book, the interpreter pattern is probably one of the most poorly described patterns. The interpreter pattern basically consists…

We have been using Elasticsearch for storing analytics data. This data stored in Elasticsearch is used in the Post Report Segmentation…


After hosting the Meta Refresh Delhi Runup Event, it was time for us at Wingify to prep up for MetaRefresh. We were very excited to…

Giving back to the community has always been a priority at Wingify, be it through open sourcing internal projects or via organizing…
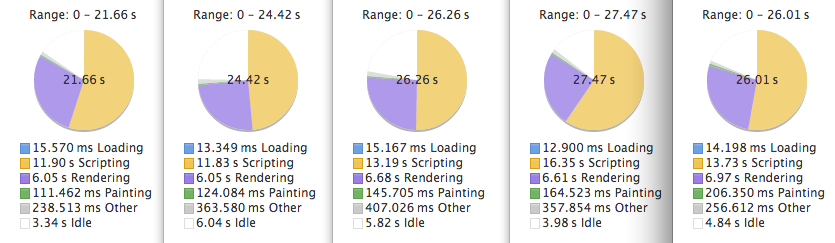

Performance matters, and an Angular.js developer would especially know it. Several watchers in a digest cycle can often be a bottleneck, and…
Elasticsearch is essentially a distributed search-engine but there have been more than one example of companies and projects using…
Meta Refresh is an event organised by HasGeek that focuses on design, user experience and the front-end web. The current iteration of Meta…

At Wingify, we believe in open source and actively seek opportunities to give back to the community. We make use of a lot of open source…
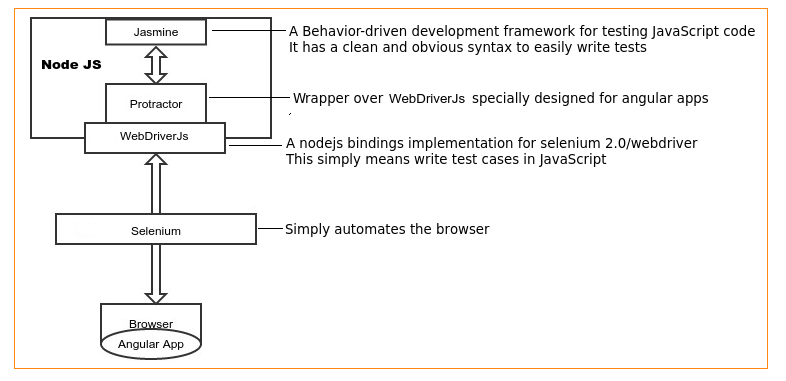

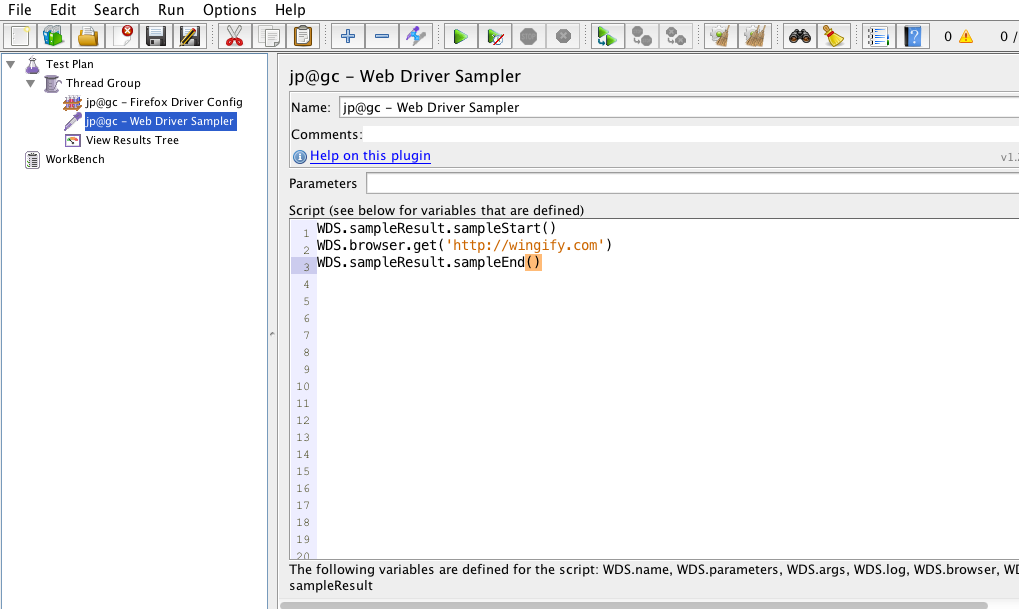
We, at Wingify, have been writing e2e test cases for our A/B testing app for the past 5 months using protractor. Writing e2e scripts is easy…

To begin with, lets talk about two of the most important things are that come to mind when we talk about performance testing. The Metrics to…

Back in November, I, along with some colleagues from Wingify went to Singapore to attend CSSConf and JSConf Asia. A part of DevFest Asia, it…


Last week, we announced that Wingify would be sponsoring the JSFoo 2014 conference in Bangalore. We have always been looking out for…
The front-end has become the heart of today's web application development, and JavaScript drives a core part of it. New technologies…
DOM Comparator is a JavaScript library that analyzes and compares two HTML strings, and returns back a diff object. It returns an output…

The Fifth Elephant is a popular conference in India around the Big Data ecosystem. It happened last week in Bangalore. And we were proud to…

We, at Wingify, handle not just our own traffic, but also the traffic of major websites such as Microsoft, AMD, Groupon, and WWF that…
We are excited to announce our sponsorship of The Fifth Elephant - a popular conference around the Big Data ecosystem. The conference will…
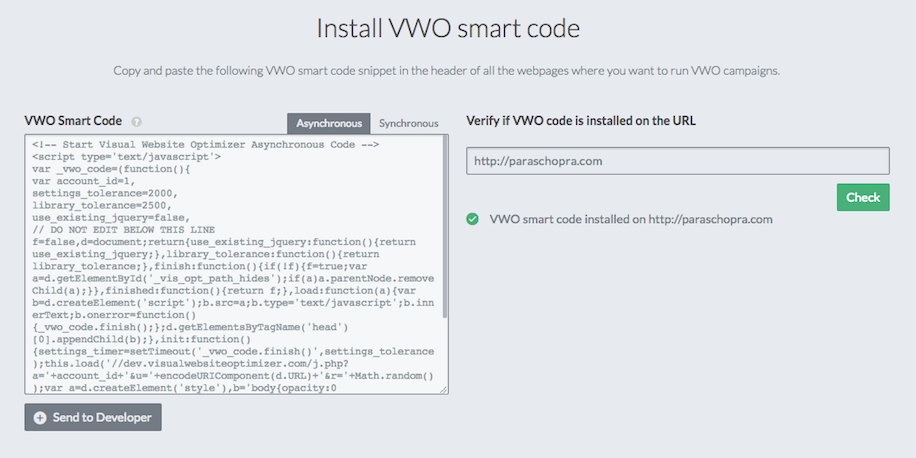

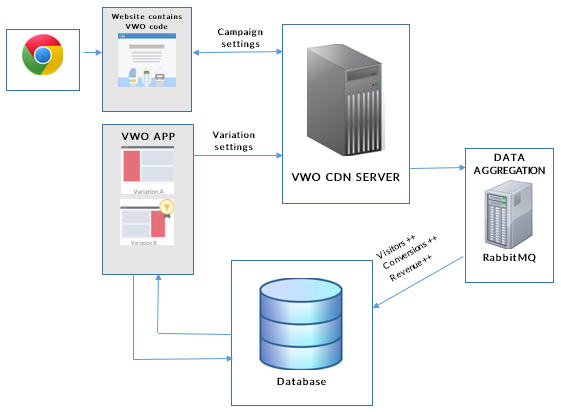
In November last year, I started developing an infrastructure that would allow us to collect, store, search and retrieve high volume data…
e2e or end-to-end or UI testing is a methodology used to test whether the flow of an application is performing as designed from start to…
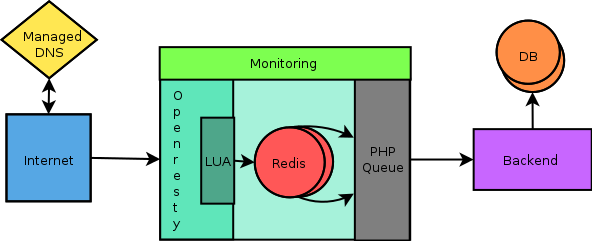
Our home-grown geo-distributed architecture based CDN allows us to delivery dynamic javascript content with minimum latencies possible…

When I got an opportunity of interning with the engineering team at Wingify it made me ecstatic because of an exciting office with…
This post is about making your web page perform better using a real world example. As you know, we recently launched a very cool animated…
In one of our previous posts, we talked about the problems we faced when communicating with frames on a different domain in our application…


Recently, we launched our first ever animated guide to A/B testing which made it to the top of HN homepage (Yay!). In this post, I'll go…
Visual Website Optimizer's editor component loads a website for editing using a proxy tunnel. It put a big restriction on what kind of…

I clearly remember the summer of 2010 when we were about to launch our product Visual Website Optimizer out of beta and almost all the…