
Leveraging Kafka Streams to reduce DB Hits
Written by Amandeep Singh
I have been working with Apache Kafka for more than 4 years now and have seen it evolve from a basic distributed commit log service (Something very similar to Transaction log or Operation log) to a full fledged tool for data pipelining and become the backbone of data collection platforms. For those who don’t know about Kafka, it was developed by LinkedIn, and was open sourced in early 2011. It is a distributed pub-sub messaging system that is designed to be fast, scalable and durable. Like other pub-sub messaging systems, Kafka maintains stream(s) of messages in topic(s). Producers are special processors that write data to Topics while, Consumers read from topics, to store data to extract some meaningful information that might be required at a later stage. Since Kafka is a distributed system, topics are partitioned and replicated across multiple nodes. Kafka lets you store streams of messages in a fault-tolerant way and allows processing these streams in near realtime.
Apache Kafka has gone through various design changes since its inception, Kafka 0.9 came out with support of High Level Consumer API, which helped in removing dependency of Apache Zookeeper. It is now only used to manage metadata of topics created in Kafka. Also, in case some Kafka node goes down or rebalance is triggered due to addition of new nodes, Zookeeper runs the leader election algorithm in a fair and consistent manner. For versions less than 0.9 Apache Zookeeper was also used for managing the offsets of the consumer group. Offset management is the mechanism, which tracks the number of records that have been consumed from a partition of a topic for a particular consumer group. Kafka 0.10 came out with out of the box support for Stream Processing. This streaming platform enables capturing flow of events and changes caused by these events, and store these to other data systems such as RDBMS, key-value stores, or some warehouse depending upon use case. I was really happy and took it for a run by doing some counting aggregations. The aggregation was fast and I hardly had to write 50 lines for it. I was very happy and impressed with results. I streamed around 2 million events in around a minute on my laptop with couple of instances only. But I never got a chance to use it in production for a year or so.
Around 3 months back when our team started stress testing backend stores by generating a lot of data, our backend stores started to give up due to the high number of insertion and updates. We didn’t have the choice to add more hardware as we were already using a lot of resources and wanted a solution that fits our current bill. Our data team had lot of discussions and I heard a lot of people talk about things like Apache Samza, Apache Spark, Apache Flink etc. Because, we have a small team, adding another component in technology stack was not a good idea and I didn’t want team to spend time learning about these technologies with product release around the corner. Since our data pipeline is built around Kafka, I started playing around with data. The idea was to convert multiple updates to the backend stores into a single update/insert to ensure that number of hits that our DB is taking is reduced. Since we process a lot of data, we thought about windowing our events based on time and aggregating them. I started to work on it and in matter of hours my streaming application was ready. We started with 1 minute window and we were surprised with the result. We were able to reduce DB hits by 70%. YES 70 PERCENT!!!!!!
Here are the screenshots from one of our servers that show the impact of window aggregation.
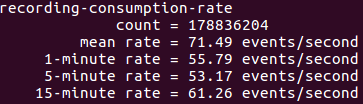
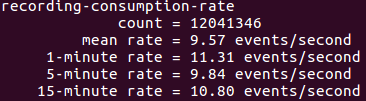
With streaming capabilities built into it, Apache Kafka has become one of the most powerful tool that allows you to store and aggregate data at insane speed. And we’ll see a gain in its adoption in coming years.
Let’s see how Kafka Streams work
Kafka Streams allows us to perform stream processing, hence requires some sort of internal state management. This internal state is managed in state stores which uses RocksDB. A state store can be lost on failure or fault-tolerant restored after the failure. The default implementation used by Kafka Streams DSL is a fault-tolerant state store using
- An internally created and compacted changelog topic (for fault-tolerance)
- One (or multiple) RocksDB instances (for cached key-value lookups). Thus, in case of starting/stopping applications and rewinding/reprocessing, this internal data needs to get managed correctly.
KStream and KTable
KStream is an abstraction of a record stream of Key-Value pairs. So if you have a click stream coming in, and you are trying to aggregate session level information, the key will be session id and the other information will be the value. Similarly for URL level aggregation, a combination of URL and session will be the key.
KTable is an abstraction of a changelog stream from a primary-keyed table. Each record in this stream is an update on the primary-keyed table with the record key as the primary key. The aggregation results are stored in KTable. Intermediate aggregation uses a RocksDB instance as key-value state store that also persists to local disk. Flushing to disk happens asynchronously to keep it fast and non blocking. An internal compacted changelog topic is also created. The state store sends changes to the changelog topic in a batch, either when a default batch size has been reached or when the commit interval is reached. A pictorial representation of what happens under the hood is given below
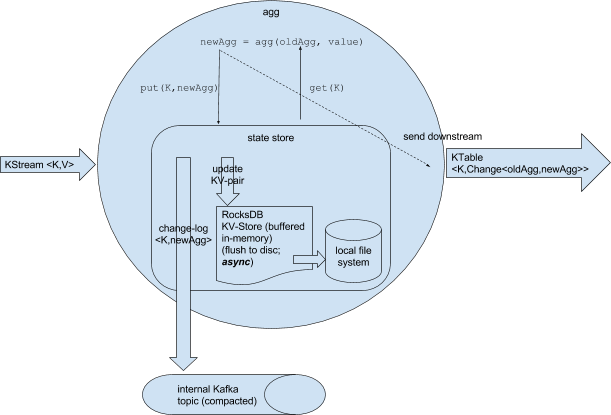
*Image is taken from Apache Kafka documentation
Kafka Streams commit the current processing progress in regular intervals. If a commit is triggered, all state stores need to flush data to disc, i.e., all internal topics needs to get flushed to Kafka. Finally, all current topic offsets are committed to Kafka. In case of failure and restart, the application can resume processing from its last commit point.
Let’s understand this with help of an example
Imagine a stream of such events coming to server for a very high traffic website. Let’s assume there is a big web gaming platform where 50K-80K concurrent users generate about 80K-120K events per second and there is a requirement to find following things:
- Number of clicks user has done in a session
- Total Pages he has viewed in a session
- Total amount of time user has spent in a session.
Let the JSON structure be as follows:
{
"uuid":"user id",
"session_id": "some uuid",
"event": "click/page_view",
"time_spent":14
}Ingestion at above mentioned pace in a DB or ensuring that these events gets stored in DB in itself is a challenge. A lot of hardware will be required to cope with this traffic as it is. Hence, it doesn’t make sense to store data directly in DB. A streaming application is a very good fit here. A streaming application is going to leverage the fact that for most of the user the clicks and page views will be concentrated in a time window. So it is possible that in 5 minutes a user might be clicking x times and giving y pageviews on an average. We can introduce a 5 minute window and club these request to form a single equivalent DB request. Hence reducing (x+y) hits to 1 hit in a window of 5 minutes. Thus reducing the traffic to 1/(x+y) of what was coming earlier.
I have written a Sample Kafka Streams Project to make it easier for you to understand. Let’s take a look at sequence diagram below. This diagram shows how various components of sample project interact with each other.
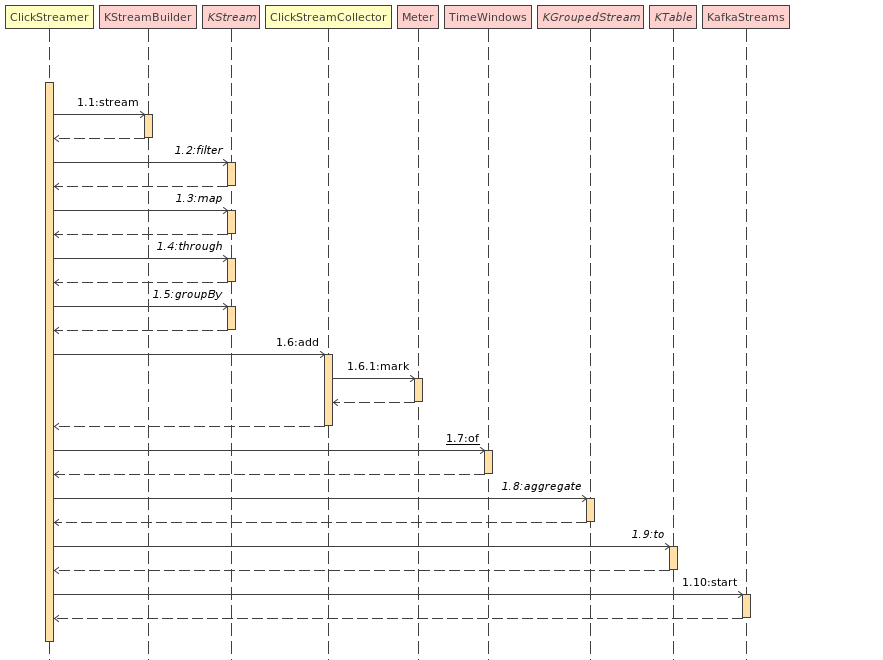
All this flow is defined with the help of Kafka Streams DSL, the code snippet is given below
//Defining Source Streams from multiple topics.
KStream<String, ClickStream> clickStream = kStreamBuilder.stream(stringSerde, clickStreamSerde,
Main.TOPIC_PROPERTIES.getProperty("topic.click.input").split(","));
//Kafka Streams DSL in action with filtering and cleaning logic and passing it through aggregation collector
clickStream
.filter((k,v) -> (v!=null))
.map((k, v) ->
new KeyValue<>(v.getSessionId(),v))
.through(stringSerde, clickStreamSerde, Main.TOPIC_PROPERTIES.getProperty("topic.click.output"))
.groupBy((k, v) -> k, stringSerde, clickStreamSerde)
.aggregate(ClickStreamCollector::new, (k, v, clickStreamCollector) -> clickStreamCollector.add(v),
TimeWindows.of(1 * 60 * 1000), collectorSerde,
Main.TOPIC_PROPERTIES.getProperty("topic.click.aggregation"))
.to(windowedSerde, collectorSerde, new ClickStreamPartitioner(), Main.TOPIC_PROPERTIES.getProperty("topic.click.summary"));It’s worth noting that for each step we need to define a serializer and deserializer. In above code snippet
- stringSerde: Defines the Serialization and Deserialization for String
- clickStreamSerde: Defines the Serialization and Deserialization for Raw click Data
- collectorSerde: Defines the Serialization and Deserialization for RocksDB intermediate storage.
- windowedSerde: Defines the serialization and Deserialization for Kafka Windowed Aggregation storage
Its very easy to implement streams over Kafka and it can be leveraged to reduce the DB traffic and for other applications, where windowing or sessionization makes sense. You can play around with this project and in case you want to reach out to me or have any doubt please drop your queries in comments section.
Happy Streaming..!