
Wingify towards Docker and Kubernetes
Written by Punit Gupta, Kamal Sehrawat
Introduction:
At Wingify, we follow microservices based architecture to leverage it's great scalability benefits. We have a lot of microservices along with a complex networking setup among them. Currently, all the services are deployed on virtual machines on the cloud. We wanted to improve this architecture set up and use the latest technologies available. To avoid all this we are moving towards Docker and Kubernetes world!
Why Docker and Kubernetes?
The problems we are facing with the existing infrastructure:
-
Standardization and consistency
- There is always an issue of a consistent/standard environment between production and development.
- Most of our time goes in creating a production like environment during development to rollout bugfixes or create any new features.
- With the new architecture, now we are more equipped to efficiently analyze and fix bugs within the application. It has drastically reduced the time wasted on "local environment issues" and in turn increased time available to fix actual issues and new feature development.
- Docker provides a repeatable production like development environment and eliminates the "it works on my machine" problem once and for all.
-
Local development
- It's not easy to develop and debug a service locally and connect it to the rest of the services running on local environment.
- Constantly redeploying on local environment to test the changes is time consuming.
-
Auto scaling
- The load on the services can never be the same all the time.
- Keeping the services up for the whole year just to handle the peak load which comes on a few days of the festive season is a waste of resources.
- Regularly benchmarking the load to scale the services with time is not an optimal way.
-
Auto service restarts
- If the service goes in a hanged state or terminates due to memory leak, resource polling deadlocks, file descriptors issues or anything else, how it is going to restart automatically?
- Although there are different tools available for multiple languages but setting them up for each service on every server is not ideal.
-
Load balancing
- Adding and maintaining an extra entry point like nginx just to provide load balancing is an overhead.
We are trying to tackle all these problems in an automated and easy way using Docker, Kubernetes and few open-source tools.
Our Journey
We started out from scratch. Read a lot of articles, documentation, tutorials and went through some existing testing and production level open source projects. Some of them solved a few of our problems, for some we found our own way and the rest of them are yet to be solved!
Below is a brief idea of all the ideas and approaches we found to solve many of our problems, the final approach we took and comparison between them:
Common repository approach
Every dockerized service starts with a Dockerfile. But the initial issue is where to put them? There will be a lot of Dockerfiles combining all the services.
There are two ways to put them:
-
Each service contains it's own dockerfile
- All the repositories have separate dockerfiles specific to that service.
-
A common repository of all dockerfiles
- All the dockerfiles of every service are added to a common repository.
Below is the comparison among them:
| Common Repository | Separate Repositories | |
|---|---|---|
| 1. | Need a proper structure to distinguish dockerfiles | Separation of concerns |
| 2. | Common Linters and Formatters | Each repo has to add the same linter and formatter repetitively |
| 3. | Common githooks to regulate commit messages, pre-commit, pre-push, etc. tasks | Same githooks in every service |
| 4. | Can contain reusable Docker base-files | No central place to put reusable dockerfiles |
| 5. | A central place for DevOps to manage the permissions of all dockerfiles | Very difficult to manage dockerfiles individually by Devops |
You may be thinking about the ease of local development using volumes in the separate repository approach. We will get back to that later and show how easy it will be in a common repository approach.
So, the common repository approach is a clear winner among them. But what about its folder structure? We gave it plenty of thoughts and finally, this is our Docker repository folder structure:
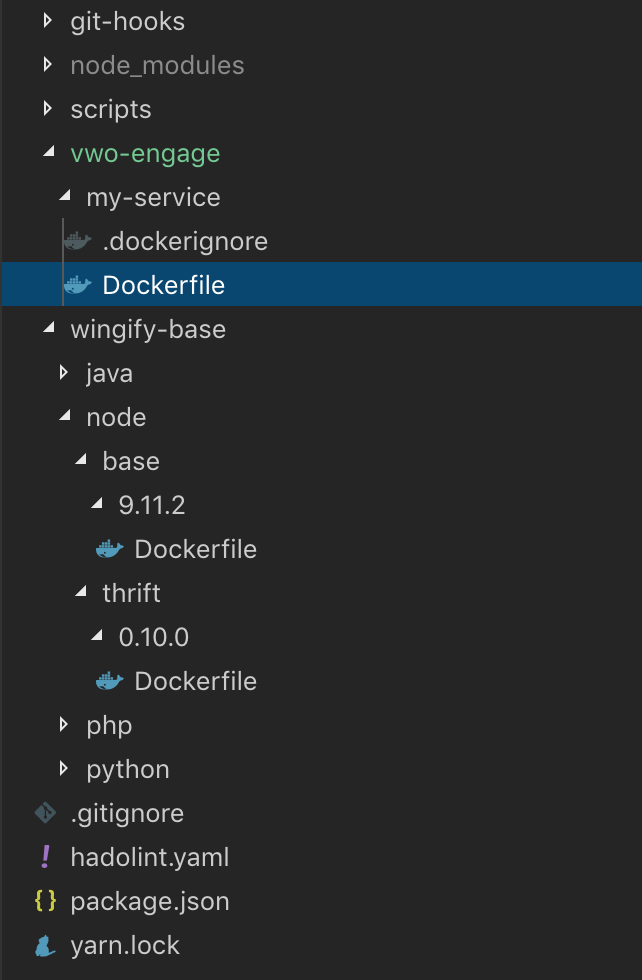
Using this folder structure has multiple advantages:
- All the services and reusable base dockerfiles are segregated.
- It becomes very clear that which dockerfile is for what service, language or plugin.
- Multiple versions can be easily served.
Next, we will discuss the reusable base images concept.
Dockerfile Linter
There are many opensource linters available for Docker files. We found hadolint meets most of the standards that Docker recommends. So, to lint all the files we just have to issue a simple command which can be easily integrated into the githooks.
hadolint **/*DockerfileDockerfile Formatter
We searched and tried multiple formatters, but none of them worked as per our requirements. We found dockfmt was close to our requirements but it also has some issues like it removes all the comments from dockerfile. So, we are yet to find a better formatter.
Reusable Docker base images
It's very common that a lot of services need the same OS, tools, libraries, etc like all the node services may need Debian stretch OS with node.js and yarn installed of a particular version. So, instead of adding them in all such Docker files, we can create some reusable, pluggable Docker base images.
Below is the example of a Node.js service which requires:
- Debian stretch OS
- Node.js version 9.11.2 + Yarn
- Apache thrift version 0.10.0
Node.js base image:
FROM debian:stretch-slim
# Install Node 9.11.x
# Defining builDeps as an argument in alphabetical order for better readability and avoiding duplicacy.
ARG buildDeps=" \
curl \
g++ \
make"
# It causes a pipeline to produce a failure return code if any command results in an error.
SHELL ["/bin/bash", "-o", "pipefail", "-c"]
# hadolint ignore=DL3008,DL3015
RUN apt-get update && apt-get install -y —- no-install-recommends $buildDeps \
# Use --no-install-recommends to avoid installing packages that aren't technically dependencies but are recommended to be installed alongside packages.
&& curl -sL https://deb.nodesource.com/setup_9.x | bash - && apt-get install -y nodejs=9.11.* \
&& npm i -g [email protected] \
&& apt-get clean \
# Remove apt-cache to make the image smaller.
&& rm -rf /var/lib/apt/lists/* Let's consider we build this with name 'wingify-node-9.11.2:1.0.5'. Where 'wingify-node-9.11.2' represents the docker image type and '1.0.5' is the image tag.
Apache thrift base image:
# Default base image
ARG BASE=wingify-node-9.11.2:1.0.5
# hadolint ignore=DL3006
FROM ${BASE}
# Declaring argument to be used in dockerfile to make it reusable.
ARG THRIFT_VERSION=0.10.0
# Referred from https://github.com/ahawkins/docker-thrift/blob/master/0.10/Dockerfile
# hadolint ignore=DL3008,DL3015
RUN apt-get update \
&& curl -sSL "http://apache.mirrors.spacedump.net/thrift/$THRIFT_VERSION/thrift-$THRIFT_VERSION.tar.gz" -o thrift.tar.gz \
&& mkdir -p /usr/src/thrift \
&& tar zxf thrift.tar.gz -C /usr/src/thrift --strip-components=1 \
&& rm thrift.tar.gz \
# Clean the apt cache on.
&& apt-get clean \
# Remove apt cache to make the image smaller.
&& rm -rf /var/lib/apt/lists/*
WORKDIR /usr/src/thrift
RUN ./configure --without-python --without-cpp \
&& make \
&& make install \
# Removing the souce code after installation.
&& rm -rf /usr/src/thriftHere, by default, we are using the above-created node's Docker image. But we can pass any other environment's base image as an argument to install thrift there. So, it's pluggable everywhere.
Finally, the actual service can use above as a base image for it's dockerfile.
Access private repository dependencies
We have multiple services that have some dependencies which are fetched from private repositories. Like in our node service, we have one of our dependencies listed in package.json as:
{
"my-dependency": "git+ssh://git@stash/link/of/repo:v1.0.0",
}Normally we need ssh keys to fetch these dependencies, but a Docker container won't be having it. Below are the few ways of solving this:
-
Option 1: Install dependencies externally (local or Jenkins) and Docker will copy them directly.
-
Advantages:
- No SSH key required by docker.
-
Disadvantages:
- Dependencies installation won't be cached automatically as it's happening outside the docker.
- Some modules like bcrypt have binding issues if not installed directly on the same machine.
-
-
Option 2: Pass SSH key as an argument in dockerfile or copy it from system to the working directory and let dockerfile copy it. Docker container can then install dependencies.
-
Advantages:
- Caching is achieved.
- No module binding issues.
-
Disadvantages:
- SSH key would be exposed in a Docker container if not handled correctly.
- Single SSH keys will have security issues and different ones will be difficult to manage.
-
-
Option 3: Host the private repos globally like our own private npm (in case of node.js) and add it's host entry on the system. Docker container can then install dependencies by fetching from our private npm.
-
Advantages:
- Caching is achieved.
- No SSH key required.
-
Disadvantages:
- One time setup of hosting.
- We need to publish the private repos each time we create a new tag.
-
Way 3 proved to be much better in our case and we moved ahead with it.
Service Dockerfile
The final dockerfile of the service implementing all above will be like:
ARG BASE=wingify-node-9.11.2-thrift-0.10.0:1.0.5
# hadolint ignore=DL3006
FROM ${BASE}
RUN mkdir -p /opt/my-service/
WORKDIR /opt/my-service
# Dependency installation separately for caching
COPY ./package.json ./yarn.lock ./.npmrc ./
RUN yarn install
COPY . .
CMD ["yarn", "start:docker"]Here '.npmrc' contains the registry which points to our own private npm. We are copying it so that Docker container can fetch our private repos from it.
Caching
Every time we change our code, we don't want Docker container to install dependencies again (unless changed). For this we divided the 'COPY' step in above dockerfile into 2 parts:
# Here we are copying the package.json and yarn.lock files and doing dependencies installation.
# This step will always be cached in Docker unless there is change in any of these files
COPY ./package.json ./yarn.lock ./.npmrc ./
RUN yarn install
COPY . .Doing all this will reduce the Docker image build time to just a few seconds!
Auto-tagging and rollback
Tagging is important for any rollback on productions. Fortunately, it's easy to do in docker. While building and pushing an image on Kubernetes we can specify the tag version with a colon. We can then use this tag in Kubernetes YAML file to deploy on the pods.
docker build -t org/my-service .
docker build -t org/my-service:1.2.3 .
docker push org/my-service .
docker push org/my-service:1.2.3 .This works fine, but it still requires a new tag every time we are building a new version of the image. This can be passed manually to a job. But what if there is auto-tagging?
First, let's find out the latest tag. Here is the command to find the latest image tag from GCP:
gcloud container images list-tags image-name --sort-by=~TAGS --limit=1 --format=jsonWe can use this in a custom node script which will return the new incremented version. We just have to pass the image name and the release type i.e. major/minor/patch to it.
// Usage: node file-name image-name patch
const exec = require('child_process').execSync;
const TAG_TYPES = {
PATCH: 'patch',
MINOR: 'minor',
MAJOR: 'major'
};
// Referenced from https://semver.org/
const VERSONING_REGEX = /^(v)?(0|[1-9]\d*)\.(0|[1-9]\d*)\.(0|[1-9]\d*)(?:-((?:0|[1-9]\d*|\d*[a-zA-Z-][0-9a-zA-Z-]*)(?:\.(?:0|[1-9]\d*|\d*[a-zA-Z-][0-9a-zA-Z-]*))*))?(?:\+([0-9a-zA-Z-]+(?:\.[0-9a-zA-Z-]+)*))?$/m;
class Autotag {
constructor(imageName = '', tagType = TAG_TYPES.PATCH) {
this._validateParams(imageName, tagType);
this.imageName = imageName;
this.tagType = tagType.toLowerCase();
}
// Private functions
_validateParams(imageName, tagType) {
if (!imageName) {
throw new Error('Image name is mandatory.');
}
if (!Object.values(TAG_TYPES).includes(tagType)) {
throw new Error(
`Invalid tag type specified. Possible values are ${Object.values(
TAG_TYPES
).join(', ')}.`
);
}
}
_fetchTagsFromGCP() {
return exec(
`gcloud container images list-tags ${
this.imageName
} --sort-by=~TAGS --limit=1 --format=json`
).toString();
}
// Public functions
increment() {
const stringifiedTags = this._fetchTagsFromGCP();
if (stringifiedTags) {
try {
const { tags } = JSON.parse(stringifiedTags)[0];
for (let i = tags.length - 1; i >= 0; i--) {
const tag = tags[i];
if (VERSONING_REGEX.test(tag)) {
let [
prefix = '',
major = 0,
minor = 0,
patch = 0
] = VERSONING_REGEX.exec(tag).slice(1);
switch (this.tagType) {
case TAG_TYPES.PATCH:
patch++;
break;
case TAG_TYPES.MINOR:
patch = 0;
minor++;
break;
case TAG_TYPES.MAJOR:
patch = 0;
minor = 0;
major++;
break;
}
return `${prefix}${major}.${minor}.${patch}`;
}
}
} catch (e) {}
}
// Return default tag if none already exists.
return '0.0.1';
}
}
try {
console.log(new Autotag(...process.argv.slice(2)).increment());
} catch (e) {
console.log(e.toString());
}Thanks Gaurav Nanda for the above script.
Production staged rollout
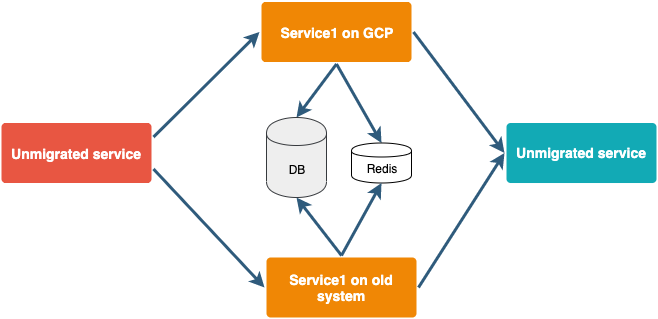
Our ultimate goal is to migrate everything from the existing setup to GCP with Docker and Kubernetes. Migrating the whole system in one go on production is time-consuming as well as risky.
To avoid this we are targeting individual services one by one. Initially, a service will run on GCP as well as on the existing server with their databases pointing to the old setup. We will open them for a few accounts at the beginning. The rest of the accounts will work as before. This will ensure that if any issue comes in a new setup, we can easily switch back to the old setup while fixing it.
Next steps
- Integrate health check APIs with Kubernetes.
- Development environment using telepresence.
- Add service discovery tool like consul.
- Add a vault system for secrets.
- Better logging.
- Integrate helm to manage the Kubernetes cluster.
- Docker image size management.
- Add support for blue green deployments.
We may be using some things differently that can be improved upon. There can be better tools that we are yet to explore. We are open to any suggestions that can help us in improving what we are already doing and what we will require in the future. This is just a start, we will try to improve in every iteration and solve new challenges.
Thanks to Gaurav Nanda for mentoring and guiding us for everything.