
PyData at Wingify - My Experience
Written by Pramod Dutta

About PyData
I recently got an opportunity to speak at the PyData, Delhi. PyData is a tech group, with chapters in New Delhi and other regions, where Python enthusiasts share their ideas and projects related to Data Analysis and Machine Learning.
Talks at PyData
There were three talks at PyData, namely Machine Learning using Tensor Flow, Data Layer at Wingify and mine, Learning Data Analysis by Scraping Websites. All the talks were thorough and excellent! In the talk, Data layer at Wingify by Manish Gill 🤓, he talked about how we handle millions of requests at Wingify.
Some of Images of the PyData Meetup Hosted by Wingify.








Background About My Talk
Let me give you a little background. It was the Friday before the PyData Meetup/Conference. Our engineering team was doing its daily tasks. I had just grabbed a coffee to alleviate my laziness. Suddenly, our engineering lead came and asked us whether anyone could present on a topic at the PyData that we were to organise the very next day. An initial speaker, who had confirmed earlier, backed out at the last moment because he had fallen sick. I could see that most of the team members tried to avoid volunteering in such a short notice and also probably because the next day was a Saturday (though this is my personal opinion). But I had something different on my mind and during this planning or confusion, I volunteered for it 🤓. I had a project that I had done, back when I was learning Python. So I offered to present it. He agreed to it and asked me to keep the presentation ready.
Preparing the Project & Slides
That Friday night, I started searching for the old files which I had used. Finally, I found all of them on my website, downloaded them and ran the code. It worked like a charm 😍. Yeah! I quickly created the slides around it, and after finishing, smiled and went to sleep at 4.30 am.
Little About the Basics of My Talk.
The presentation that I gave was on Learning Data Analysis by Scraping Websites. During my college days, we heavily used the BeautifulSoup Library in Python to scrape websites for the many personal projects. During this project, I got the idea to scrape data from the websites which aggregated movies related data. By doing that, I thought that I could create a list of all movies that I must definitely watch. The movies had to satisfy the following criteria:
- Release date >= 2000
- Rating > 8
It was not the best idea at that time to scrape websites and then analyse(Data frame). But I learned a lot of things by scraping data from the website using Beautifulsoup, then analyzing data using Pandas, visualizing data using MatplotLib (a Python library) and finally coming to conclusion about my movies recommendation.
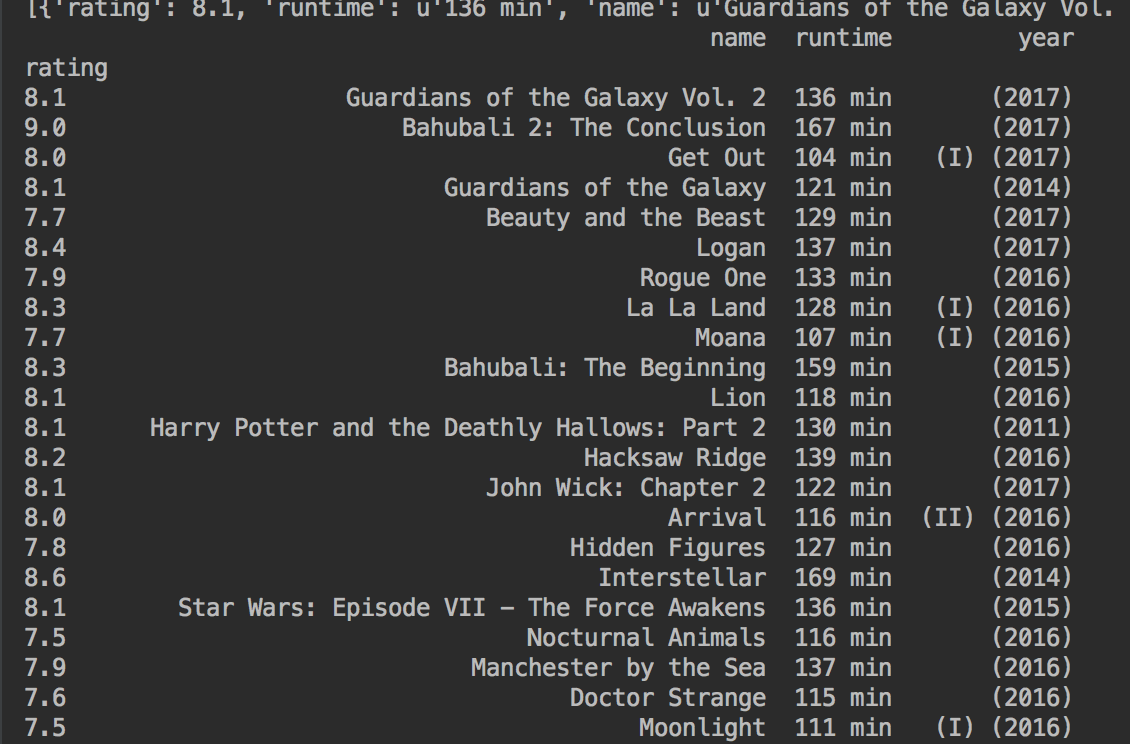
Coming back to the objective - Finding and sorting the movies released between 2000-2017 in the order of relevance (I didn't want to watch movies < 2000).
Below is the code to scrape IMDB for movies data from 2000-2017.
from bs4 import BeautifulSoup
import urllib2
def main():
print("** ====== Data Extracting Lib -- by Promode ===== **")
testUrl = "http://www.imdb.com/search/title?at=0&count=100&\
groups=top_1000&release_date=2000,2017&sort=moviemeter"
pageSource = urllib2.urlopen(testUrl).read()
soupPKG = BeautifulSoup(pageSource, 'lxml')
titles = soupPKG.findAll("div",class_='lister-item mode-advanced')
mymovieslist = []
mymovies = {}
for t in titles:
mymovies = {}
mymovies['name'] = t.findAll("a")[1].text
mymovies['year'] = str(t.find("span", "lister-item-year").text).replace('','')
mymovies['rating'] = float(str(t.find("span", "rating-rating").text)\
.replace('','')[0:-3])
mymovies['runtime'] = t.find("span", "runtime").text
mymovieslist.append(mymovies)
print mymovieslist
if __name__=="__main__":
main()Click here to have a look at the full source code.
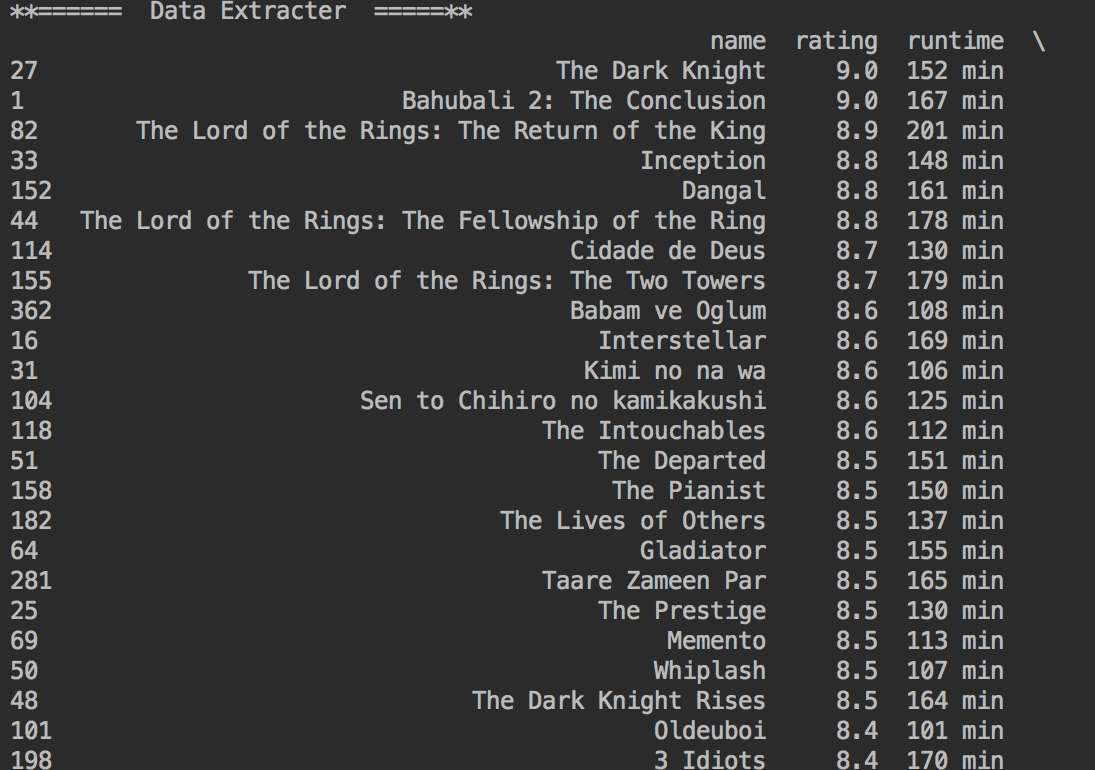
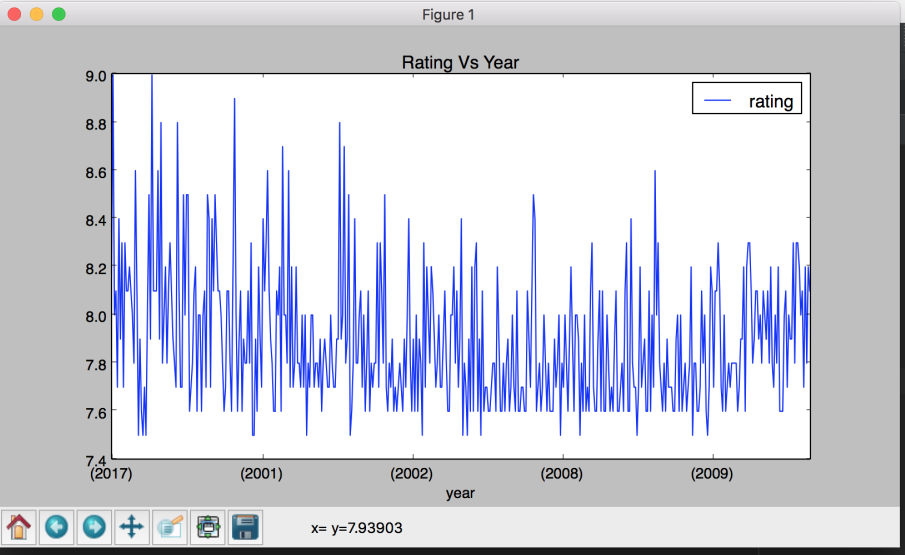
You can see the trends like Maximum Rating - Sorted by Rating, Year Vs Rating Trend
Take away from the Talk
With this method, you would have winner's data from the data set. For example, suppose you want to create a Cricket Team(IPLT20) which has the maximum probability to win the match, what you can do is parse the IPLT20) website for last 5 years' data and select the top 5 batsmen and 6 bowlers 😎.
Conclusion
I totally understand that this may not be the best project for the data analysis. I am still learning and I showed what I had done. I believe that it served my purpose.
I will be doing more research on data analysis in Python. Thanks for reading this. Below is my talk slides:
Slides:
Slides :-