
Dynamic CDN
Written by Ankit Jain
We, at Wingify, handle not just our own traffic, but also the traffic of major websites such as Microsoft, AMD, Groupon, and WWF that implement Visual Website Optimizer (VWO) for their website optimization. VWO allows users to A/B test their websites and optimize conversions. With an intuitive WYSIWYG editor, you can easily make changes to your website and create multiple variations you can A/B test. When a visitor lands on your website, VWO selects one of the variations created in the running campaign(s) and the JavaScript library does the required modifications to generate the selected variation based on the URL visited seen by the visitor. Furthermore, VWO collects analytics data for every visitor interaction with the website and generates detailed reports to help you understand your audience behavior and provide deeper insight of your business results.
Here is a very high-level overview of what goes on behind the scenes:
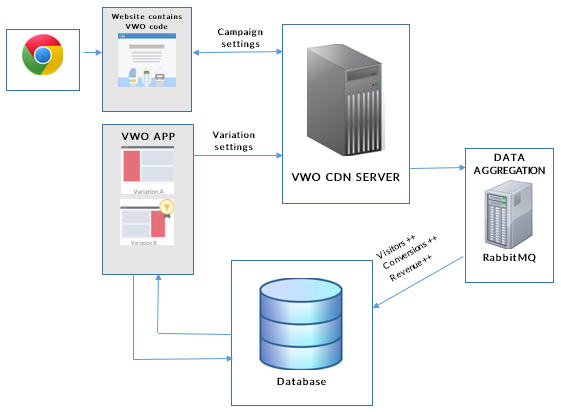
How it started
Back in the days, we deployed one server in the United States that had the standard LAMP stack running on it. The server stored all changes made to a website using VWO app, served our static JS library, collected analytics data, captured visitor data, and saved it in a MySQL database.
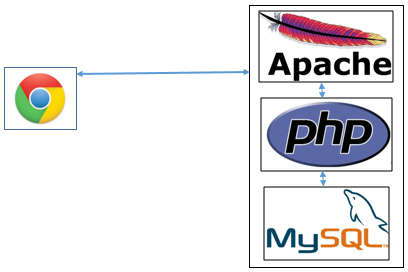
This implementation worked perfectly for us initially, when we were serving a limited number of users. However, as our user base kept growing, we had to deploy additional Load Balancers and Varnish cache servers (each having 32GB of RAM and we had 8 such servers to meet our requirements) to make sure that we cache the content for every requested URL and serve back the content in the least possible time.
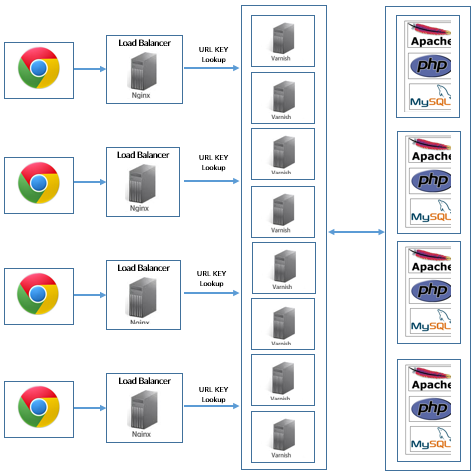
Gradually, we started using these servers only for serving JS settings and collecting analytics data, and started using Amazon's CloudFront CDN for serving static JS library.
Issues we faced
This worked great for a while till we hit our traffic to more than 1k requests per sec. With so much of traffic coming in and the increasing number of unique URLs being tested, the system started failing. We experienced frequent cache misses and Varnish required more RAM to cope up with the new requirements. We knew we had hit the bottom-end there and quickly realized that it was time for us to stop everything and get our thinking caps back on to redesign the architecture. We now needed a scalable system that was easier to maintain, and would cater to the needs of our users from various geo locations.
The new requirements
Today, VWO uses a Dynamic CDN built in-house that can cater to users based in any part of the world. The current implementation offers us with the following advantages in comparison with other available CDNs:
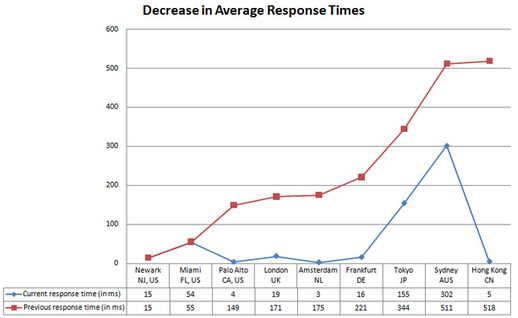
- Capability of handling almost any amount of requests at average response times of 50ms
- Handles 10k+ request/sec per node (8GB RAM). We have benchmarked this system to handle 50k requests/sec per node in our current production scenario
- 100% uptime
- Improved response time and data acquisition as the servers are closer to the user, thus minimizing the latency and increasing the chances of successful delivery of data
- Considerable cost savings as compared to the previous system
- Freedom to add new nodes without any dependencies on other nodes
Implementation challenges and technicalities
The core issue we had to resolve was to avoid sending the same response for all the requests coming from a domain or a particular account. In the old implementation, we were serving JSON for all the campaigns running in an account, irrespective of a campaign running on that URL. This loaded unnecessary JS code, which might not be useful for a particular URL, thereby increasing load time of the website. We knew how page-load time is crucial for online businesses and how it directly impacts their revenue. In the marketing world, the users are less likely to make purchases from a slow loading website as compared to a fast loading website.
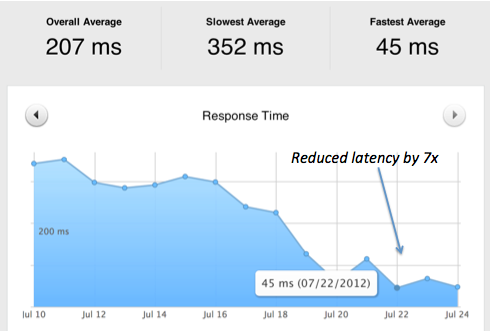
It is important to make sure that we only serve relevant content based on the URL of the page. There are two ways to do this:
- Cache JSON for all the URLs and use cache like Varnish (the old system).
- Cache each campaign running in an account and then build/combine the settings dynamically for each URL. This approach is the fastest possible way of implementation with least amount of resources.
With the approach identified, we started looking for nodes that could do everything for us - generate dynamic JSON on the basis of request, serve static JS library, and handle data acquisition. Another challenge was to make these nodes a part of distributed system that spreads across different geographies, with no dependency on each other while making sure that the request is served from the closest location instead of nodes only in the US. We had written a blog post earlier to explain this to our customers. Read it here.
OpenResty (aka. ngx_openresty) our current workhorse, is a full-fledged web application server created by bundling the standard Nginx core with different 3rd-party Nginx modules and their external dependencies. It also bundles Lua modules to allow writing URL handlers in Lua, and the Lua code runs within the web server.
From 1 server running Apache + PHP to multiple nodes involving Nginx (load balancer) -> Varnish (cache) -> Apache + PHP (for cache miss + data collection), to the current system where each node in itself is capable of handling all types of requests. We serve our static JS library, JSON settings for every campaign and also use these servers for analytics data acquisition.
The following section describes briefly the new architecture of our CDN and how VWO servers handle requests:
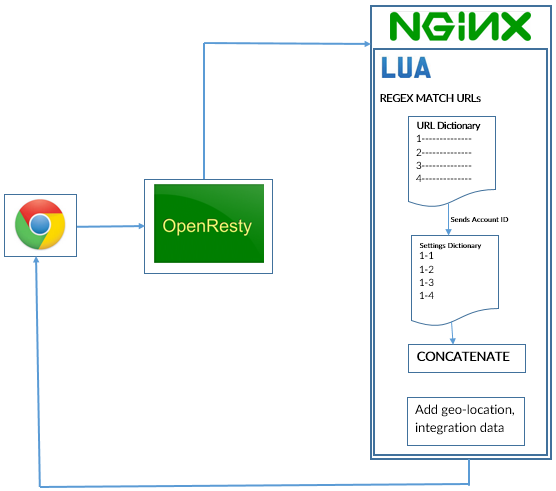
- We use Nginx-Lua Shared Dictionary, an in-memory store shared among all the Nginx worker processes to store campaign specific data. Memcached is used as the first fallback if we have to restart the OpenResty server (it resets the shared dictionary). Our second fallback is our central MySQL database. If any request fails at any level, [the system] fetches it from the lower layer and responses are saved in all the above levels to make them available for the next request.
- Once the request hits our server to fetch JSON for the campaigns running on a webpage, VWO runs a regex match for the requested URL with the list of URL regex patterns stored in the Nginx-Lua shared dictionary (key being Account ID, O(1) lookup, FAST!). This returns the list of campaign IDs valid for the requested URL. All the regex patterns are compiled and cached in worker-process level and shared among all requests.
- Next, VWO looks up for the campaign IDs (returned after matching the requested URL) in the Nginx-Lua shared dictionary, with Account ID and Campaign ID as key (again an O(1) lookup). This returns the settings for all campaigns, which are then combined and sent with some additional data in response based on requests such as geo-location data, 3rd party integrations specific code, etc. We ensure that the caching layer does not have stale data and is updated within a few milliseconds. This offers us advantage in terms of validation time taken by most CDNs available.
- To ensure that the request is served from the closest server to the visitor, we use managed DNS services from DynECT that keeps a check on the response times from various POPs and replies with the best possible server IPs (both in terms of health and distance). This helps us ensure a failsafe delivery network.
- To ensure that the system captures analytics data, all data related to visitors, conversions and heatmaps is sent to these servers. We use Openresty with Lua for collecting all incoming data. All the data received at Openresty end is pushed to a Redis server running on all these machines. The Redis server writes the data as fast as possible, thereby reducing the chance of data loss. Next, we move data from the Redis servers to central RabbitMQ. This incoming data is then used by multiple consumers in various ways and stored at multiple places for different purposes. You can check our previous post Scaling with Queues to understand more about our data acquisition setup.
As our customers keep growing and our traffic keeps growing, we will be able to judge better about our system, how well it scales and what problems it has. And as VWO grows and becomes a better and better, we will keep working on our current infrastructure to improve it and adjust it for our needs. We would like to thank agentzh (YichunZhang) for building OpenResty and for helping us out whenever we were stuck with our implementation.
We work in a dynamic environment where we collaborate and work towards architecting scalable and fault-tolerant systems like these. If these kind of problems and challenges interest you, we will be happy to work with you. We are hiring!