
Kafka Streams Stateful Ingestion with Processor API
Written by Aditya Gaur
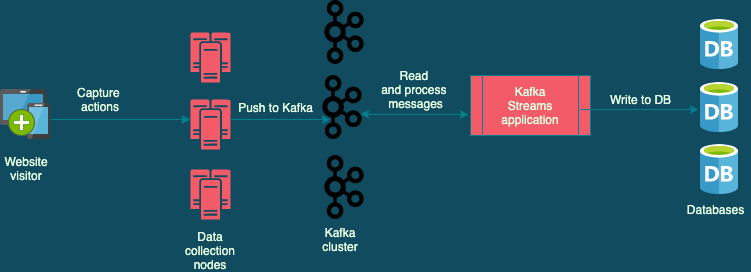
At Wingify, we have used Kafka across teams and projects, solving a vast array of use cases. So, when we had to implement the VWO Session Recordings feature for the new Data platform, Kafka was a logical choice, with Kafka Streams framework doing all the heavy lifting involved with using Kafka Consumer API, allowing us to focus on the data processing part. This blog post is an account of the issues we faced while working on the Kafka Streams based solution and how we were able found a way around them.
The Problem
Batching write operations to a database can significantly increase the write throughput. It can also become a necessity in situations when you have to adhere to quotas and limits. In one of our earlier blog posts, we discussed how the windowing and aggregation features of Kafka Streams allowed us to aggregate events in a time interval and reduce update operations on a database. What we wanted to do for the recordings feature was quite similar. The way we wanted to batch updates to an external sink for a particular customer's data was to fire an update if either :
- The number of events for that customer exceeded a certain threshold.
- Or, a certain amount of time had elapsed since the last update.
Implementation
The batching strategy we wanted to implement was similar to functionality frameworks like Apache Beam provide through the concept of windows and triggers. Kafka Streams provides the functionality of time-based windows but lacks the concept of triggers. Nevertheless, with an application having nearly the same architecture in production working well, we began working on a solution.
The Solution - first attempt
Our first solution used Kafka Streams DSL groupByKey() and reduce() operators, with the aggregation being performed on fixed interval time windows.
Visitor Java class represents the input Kafka message and has JSON representation :
{
"customerId": 1234,
"visitorId": "42F77D2D52A343F487C313BC77A312D0",
"action": "click"
}VisitorAggregated Java class is used to batch the updates and has the JSON representation :
{
"customerId": 1234,
"events": [
{
"visitorId": "42F77D2D52A343F487C313BC77A312D0",
"action": "click"
},
{
"visitorId": "198CCCA1A0F74BF19FDC80F282F21A5C",
"action": "scroll"
}
]
}The snippet below describes the code for the approach
Serde<Visitor> visitorSerde = Serdes.serdeFrom(
new JsonSerializer<>(Visitor.class),
new JsonDeserializer<>(Visitor.class));
Serde<VisitorAggregated> visitorAggregatedSerde = Serdes.serdeFrom(
new JsonSerializer<>(VisitorAggregated.class),
new JsonDeserializer<>(VisitorAggregated.class));
StreamsBuilder streamsBuilder = new StreamsBuilder();
Duration windowDuration = Duration.ofMillis(10000);
TimeWindows window = TimeWindows.of(windowDuration).advanceBy(windowDuration);
streamsBuilder
.stream(KAFKA_TOPIC, Consumed.with(Serdes.String(), visitorSerde)) (1)
.filter((k, v) -> v != null)
.map((k, v) ->
KeyValue.pair(v.getCustomerId(), new VisitorAggregated(v))) (2)
.groupByKey(Grouped.with((Serdes.Integer()), visitorAggregatedSerde))
.windowedBy(window.grace(Duration.ZERO))
.reduce(VisitorAggregated::merge) (3)
.suppress( (4)
Suppressed.untilTimeLimit(windowDuration,
Suppressed.BufferConfig.unbounded()))
.toStream()
.foreach((k, v) -> writeToSink(k.toString(), v)); (5)
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), streamsConfig);
kafkaStreams.start();A brief overview of the above code snippet:
stream()reads Kafka Messages fromKAFKA_TOPICtopic and converts them to Java objects using JSON Deserializer.- To perform aggregation based on customerId,
map()performs a key changing operation and remaps all the key-value pairs with customerId as the key. groupByKey()andreduce()implement the aggregation logic on 10 seconds long fixed-time windows for each key.merge()is a static method forVisitorAggregatedclass where the aggregation logic is defined.- The output of
reduce()is aKTableobject andsuppress()ensures aggregation results are forwarded only after the window has expired, suppressing all intermediate results. forEach()transform writes aggregation results to the external sink viawriteToSink().
In theory, all looked good, and an existing Kafka Streams application having nearly the same logic working well in production increased our confidence in this solution. However, a significant deviation with the Session Recordings feature was the size of the payload and latency requirements. VWO Session Recordings capture all visitor interaction with a website, and the payload size of the Kafka messages is significantly higher than our other applications that use Kafka. Also, we expect the updates to be in near real-time.
Issues with groupByKey() and reduce() DSL operators approach
With few load test runs, we observed certain areas of concern
-
Before a
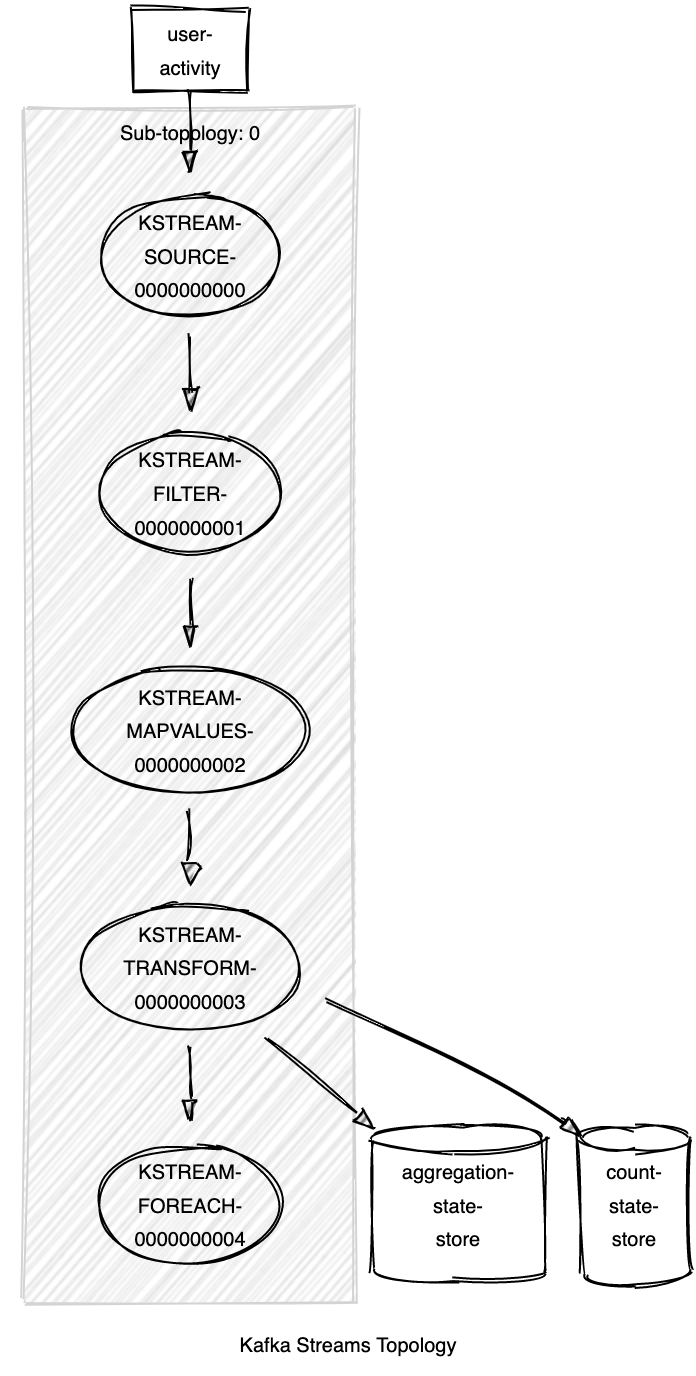
groupByKey()transform, we need to perform a key changing operation(Step 2 in the above code snippet). As a result, the Kafka Streams framework is forced to perform a repartition operation (similar to the shuffle step in the Map/Reduce paradigm). This involves creating an internal topic with the same number of partitions as the source topic and writing records with identical keys to the same partition. After records with identical keys are co-located to the same partition, aggregation is performed and results are sent to the downstream Processor nodes.Due to repartition, what was initially one single topology, is now broken into two sub-topologies and the processing overhead of writing to and reading from a Kafka topic is introduced, along with duplication of the source topic data. This overhead meant that messages already having higher payload size, would leave an even higher footprint on the Kafka broker.
-
The result of the aggregation step is a
KTableobject and is persisted and replicated for fault tolerance with a compacted Kafka changelog topic. Also, the KTable object is periodically flushed to the disk. In case of a consumer rebalance, the new/existing Kafka Stream application instance reads all messages from this changelog topic and ensures it is caught up with all the stateful updates/computations an earlier consumer that was processing messages from those partitions made. Like the repartition topic, the changelog topic is an internal topic created by the Kafka Streams framework itself.An additional changelog topic and a persistent KeyValue store meant more storage overhead on top of the repartition topic and slower startup times for the application as well since they had to read from this topic. State store replication through changelog topics is useful for streaming use cases where the state has to be persisted, but it was not needed for our aggregation use case as we were not persisting state.
 Internal repartition and change-log topics created by Kafka Streams
Internal repartition and change-log topics created by Kafka Streams
- Our expectation of window-based aggregation was that for each key we would receive the results in the downstream Processor nodes strictly after the expiration of the window. However, the result of aggregation stored in a
KTableobject is flushed from the cache and forwarded downstream either when the commit interval has elapsed or themax-cachesize is reached. This meant that we lacked fine-grained control over when the results of aggregation will be forwarded for a particular customer. Also, for keys having a lower rate of incoming messages, aggregation results can take a long time to be forwarded and reflected in the database. Despite tweaking with configuration parameters and using Kafka Streams constructs like commit interval, cache flushes, andKTable#supress(), we were unable to ensure that all updates were made to the external sink in a time-bound manner.
The Solution - Processor API
The challenges we faced with a time-based windowing and groupByKey() + reduce() approach indicated that it was not the most ideal approach for our use case. We needed something above what the Kafka Streams DSL operators offered. After some research, we came across the Processor API.
Processor API
Processor API is a low-level KafkaStreams construct which allows for:
- Attaching KeyValue stores to KafkaStreams Processor nodes and performing read/write operations. A state store instance is created per partition and can be either persistent or in-memory only.
- Schedule actions to occur at strictly regular intervals(wall-clock time) and gain full control over when records are forwarded to specific Processor Nodes.
Transformer Interface
Using the Processor API requires manually creating the streams Topology, a process that is abstracted away from the users when using standard DSL operators like map(), filter(), reduce(), etc. The Transformer interface strikes a nice balance between the ease of using Kafka Streams DSL operators and the capabilities of low-level Processor API.
From Kafka Streams documentation :
The Transformer interface is for stateful mapping of an input record to zero, one, or multiple new output records (both key and value type can be altered arbitrarily). This is a stateful record-by-record operation, i.e, transform(Object, Object) is invoked individually for each record of a stream and can access and modify a state that is available beyond a single call of transform(Object, Object). Additionally, this Transformer can schedule a method to be called periodically with the provided context.
Implementation
The Transformer interface having access to a key-value store and being able to schedule tasks at fixed intervals meant we could implement our desired batching strategy. Below is the code snippet using the transform() operator.
StreamsBuilder streamsBuilder = new StreamsBuilder();
streamsBuilder.addStateStore( (1)
Stores.keyValueStoreBuilder(
Stores.inMemoryKeyValueStore(AGGREGATE_KV_STORE_ID),
Serdes.Integer(), visitorAggregatedSerde
).withLoggingDisabled().withCachingDisabled());
streamsBuilder.addStateStore(
Stores.keyValueStoreBuilder(
Stores.inMemoryKeyValueStore(COUNT_KV_STORE_ID),
Serdes.Integer(), Serdes.Integer()
).withLoggingDisabled().withCachingDisabled());
streamsBuilder
.stream(KAFKA_TOPIC, Consumed.with(Serdes.String(), visitorSerde))
.filter((k, v) -> v != null)
.mapValues(VisitorAggregated::new)
.transform(() -> (2)
new VisitorProcessor(AGGREGATE_THRESHOLD, AGGREGATE_DURATION),
AGGREGATE_KV_STORE_ID,
COUNT_KV_STORE_ID)
.foreach((k, v) -> writeToSink(k, v));
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), streamsConfig);
Runtime.getRuntime().addShutdownHook(new Thread(kafkaStreams::close)); (3)
kafkaStreams.start();- We are using In-memory key-value stores for storing aggregation results and have turned off changelog topic-based backup of the state store. We can do so as the aggregation results don't have to be persisted after they have been forwarded. In case updates to the key-value store have to be persisted, enabling disk
caching()and changelog topiclogging()is recommended. - In the
transformProcessor, we have attached the state storesAGGREGATE_KV_STORE_ID,COUNT_KV_STORE_ID, and supply an instance ofVisitorProcessorclass, which implements theTransformerinterface.AGGREGATE_THRESHOLDandAGGREGATE_DURATIONspecify the batching configuration parameters. - A background thread listens for the termination signal and ensures a graceful shutdown for the Kafka streams application via
close().
VisitorProcessor implements the init(), transform() and punctuate() methods of the Transformer and Punctuator interface.
public class VisitorProcessor implements Transformer<String, VisitorAggregated>, Punctuator {
private Duration interval;
private ProcessorContext ctx;
private KeyValueStore<Integer, VisitorAggregated> aggregateStore;
private KeyValueStore<Integer, Integer> countStore;
private Integer threshold;
public VisitorProcessor(Integer threshold, Duration interval) {
this.threshold = threshold;
this.interval = interval;
}
@Override
public void init(ProcessorContext context) {
this.ctx = context;
this.aggregateStore = (KeyValueStore) context.getStateStore(Main.AGGREGATE_KV_STORE_ID);
this.countStore = (KeyValueStore) context.getStateStore(Main.COUNT_KV_STORE_ID);
this.ctx.schedule(interval, PunctuationType.WALL_CLOCK_TIME, this::punctuate);
}
@Override
public KeyValue<String, VisitorAggregated> transform(String key, VisitorAggregated visitor) {
KeyValue<String, VisitorAggregated> toForward = null;
Integer stateStoreKey = visitor.getCustomerId();
countStore.putIfAbsent(stateStoreKey, 0);
aggregateStore.putIfAbsent(stateStoreKey, new VisitorAggregated(visitor.getCustomerId()));
Integer aggregateCount = countStore.get(stateStoreKey) + 1;
VisitorAggregated visitorAggregated = visitor.merge(aggregateStore.get(stateStoreKey));
aggregateStore.put(stateStoreKey, visitorAggregated);
countStore.put(stateStoreKey, aggregateCount);
if (aggregateCount >= threshold) {
toForward = KeyValue.pair(key, visitorAggregated);
countStore.delete(stateStoreKey);
aggregateStore.delete(stateStoreKey);
}
return toForward;
}
private void forwardAll() {
KeyValueIterator<Integer, VisitorAggregated> it = aggregateStore.all();
while (it.hasNext()) {
KeyValue<Integer, VisitorAggregated> entry = it.next();
ctx.forward(entry.key, entry.value);
aggregateStore.delete(entry.key);
countStore.delete(entry.key);
}
it.close();
}
@Override
public void punctuate(long timestamp) {
forwardAll();
}
@Override
public void close() {
forwardAll();
}
}init()initializes the state stores and schedulespunctuate()to strictly execute once for every fixed time interval. One state store maintains a count of events per customer and other the results of the aggregation.transform()is called for all records received from upstream Processor nodes and returns a key-value pair to be processed by downstream nodes. On receiving a record we perform an increment operation for the key (customerId). If the count increases beyond a threshold, the aggregation result is forwarded before the timer is called by thepunctuate()method, and the state is flushed for the particular key in both state stores. Null values returned from this method are ignored by the downstream Processor nodes.punctuate()invokesforwardAll(), which iterates over all the key-value pairs in the aggregation state store, forwards all key-value pairs at the end of the aggregation interval to downstream Processor nodes, and clears both state stores.close()callingforwardAll()ensures that whenever the Kafka Streams application receives a shutdown signal, all records in the in-memory store are forwarded before the process exits.
Conclusion
Using state stores and Processor API, we were able to batch updates in a predictable and time-bound manner without the overhead of a repartition. Also, using in-memory key-value stores meant that the Kafka Streams application left a minimal footprint on the Kafka cluster. You can find the complete working code here. Should you have any feedback or doubts regarding this article you can share them via comments.