
Automating Tedious Managerial Tasks
Written by Kandeel Chauhan

Client issue assignment and tracking.
We at Wingify take our client issues very seriously and have built processes to get the desired resolutions in the fastest and most efficient ways possible. Needless to say, the QA engineers are at the heart of this process. We follow a process where the QA team is the first in line to diagnose, debug and revert to all client issues passed on by the customer support team. Additionally, we have defined a 4-hour SLA for the first response to all client issues.
As the process was started, the round-robin assignment was done manually by a senior member of the team, who took into account some parameters: people on leaves and area-wise assignment bias, among other variables while assigning the issues. The drawbacks to the manual process are quite obvious:
- A person can check for issues (in Jira) only a few times a day, which means issues remain un-assigned for hours putting our desired SLA at risk.
- The bandwidth of a senior team member is blocked - He has to keep an eye out on new issues logged, who all are on leave, and maintain a sheet with the history of the assignment so he can assign in a round-robin.
The solution: When it's tedious and mundane - Automate it!
We managed to automate this task by automating the below steps and now have an automated system for client-issue assignments. It has helped us increase efficiency by consistently meeting our SLAs and helping free the bandwidth of team members who can now focus on more impactful work.
Step 1: The script runs querying (Jira) every few minutes for any new client issues raised. – We use Jenkins for the scheduled runs.
Step 2: Parses the response of Jira query APIs and fetches a list of open issues and their details like summary and description of the tickets. – We use a framework that is essentially a wrapper over RestAssured (explained in some detail later in the article.)
Step 3: Filter out issues in case they are already assigned and being worked upon.
Step 4: Figure out who the issue is to be assigned to based on:
- Certain assignment biases, the script figures out based on various Jira fields.
- Skip team members on leave.
- A basic round-robin system among the eligible team members.
Step 5: Communicate by tagging the assignee and the issue ID on a pre-defined Slack channel.
Now that you know what we do, let's get deeper into how we do it.
We have open-sourced our Rest Assured framework which can be accessed here: https://github.com/wingify/rest-api-testing-framework
In the framework you can notice the following useful components:
- The Rest Assured libraries.
-
Google Sheets Utils - This is where the functionality to interact with Google Sheets using Google Sheet APIs is written. We use Google Sheets to maintain the attendance roster, assignment history, and the round-robin flow. The advantage of using Google Sheets over other options like CSV, JSON, etc. is that anyone can update details without having to access the code base.
The image shows a simple reusable function created to write data into Google Sheets.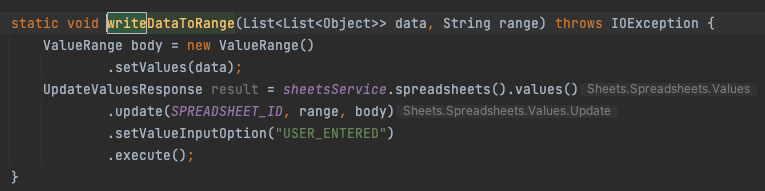
-
Jira Utils - Contains functionalities to pull data from Jira using Jira Query Language (JQL) queries and parse the responses.
The image shows a reusable function created to fetch the results of any JQL query.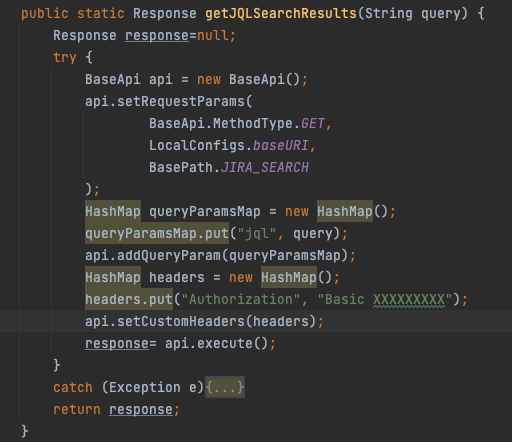
-
Slack Utils - Has code to push customized messages as alerts to Slack channels tagging the assignees.
The image shows a reusable function created to push messages to Slack channels.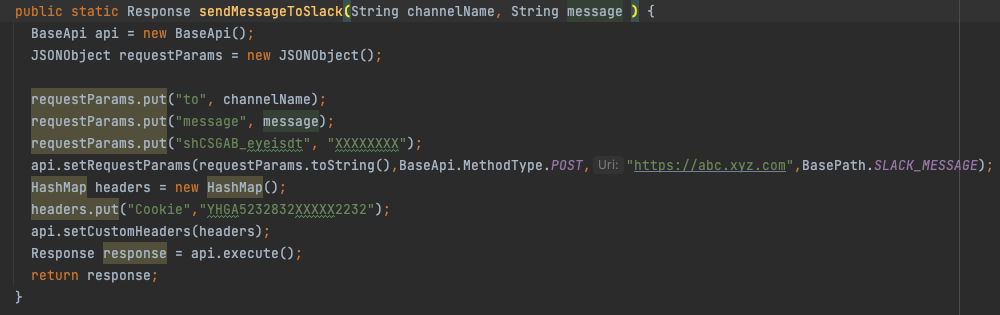
- The Test Class - Test NG annotations are used to create groups for various alerts, this gives us the ability to schedule our builds flexibly. For instance, the 'client issue debugging' alert runs every 30 mins, while 'long pending issues' are run just twice a week.
Alert for long-open client issues
We have leveraged the above code for another solution – Alert the team about long-pending client issues. Since the implementation is already shared in the git repo. We will just touch upon the process in this article.
Classification: Any issue that has been open for more than 7 days is classified as a "long pending issue". There are certain exceptions to this rule, for example, an issue that is pending confirmation on the client's end. – These exceptions are filtered out at the Jira Query level itself using various Jira fields and their values.
Alert format: Our script is executed twice a week and shares a list of these issues on Slack and also tags the assignees. This alert helps the team members as a reminder as they might be involved in several tasks in a given sprint.
Benefits: It has helped us turn the team's focus to these issues and we have seen the number of these long pending issues go down since the alert was put in place. And the best part is – it requires no manual intervention and hence, happens like clockwork.
Once you have this framework in place, you can leverage it to pull out any data from Jira, create alerts and automated reports which may suit your use case. For instance, we are building a "possible SLA miss" alert, and a "quality trend" report using the framework mentioned above. We will keep the repository updated as and when we roll out the new reports.
We would also encourage contributions to the repo in case anyone wishes to help us further improve this capability. Also, do let us know in the comments section below if you are using a similar solution in your organization albeit with a different approach.