
Fast Storage with RocksDB
Written by Rohit Yadav
June 13, 2014 — 4 Min Read | 9 Comments
In November last year, I started developing an infrastructure that would allow us to collect, store, search and retrieve high volume data. The idea was to collect all the URLs on which our homegrown CDN would serve JS content. Based on our current traffic, we were looking to collect some 10k URLs per second across four major geographic regions where we run our servers.
In the beginning we tried MySQL, Redis, Riak, CouchDB, MongoDB, ElasticSearch but nothing worked out for us with that kind of high speed writes. We also wanted our system to respond very quickly, under 40ms between internal servers on private network. This post talks about how we were able to make such a system using C++11, RocksDB and Thrift.
First, let me start by sharing the use cases of such a system in VWO; the following screenshot shows a feature where users can enter a URL to check if VWO SmartCode was installed on it.
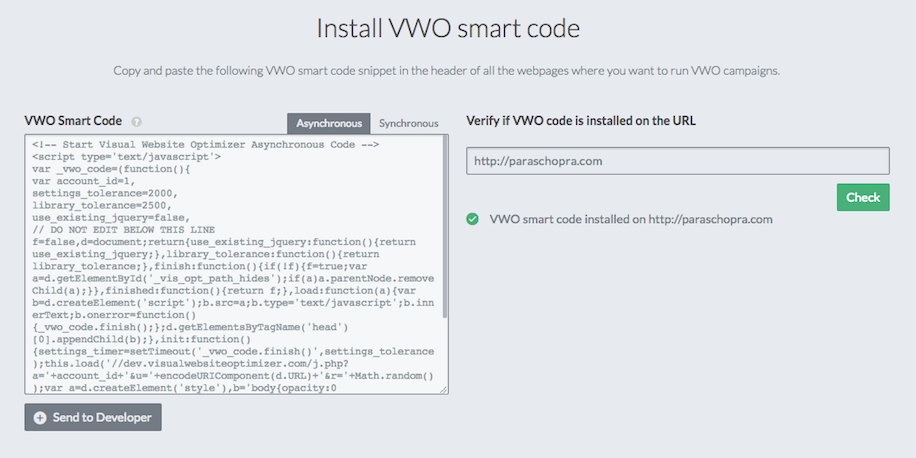
VWO SmartCode checker
The following screenshot shows another feature where users can see a list of URLs matching a complex wildcard pattern, regex pattern, string rule etc. while creating a campaign.
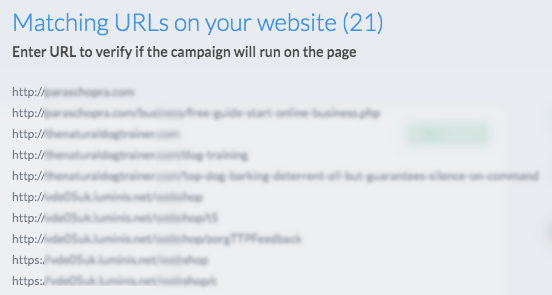
VWO URL Matching Helper
I reviewed several opensource databases but none of them would fit our requirements except Cassandra. In clustered deployment, reads from Cassandra were too slow and slower when data size would grew. After understanding how Cassandra worked under the hood such as its log structured storage like LevelDB I started playing with opensource embeddable databases that would use similar approach such as LevelDB and Kyoto Cabinet. At the time, I found an embeddable persistent key-value store library built on LevelDB called RocksDB. It was opensourced by Facebook and had a fairly active developer community so I started playing with it. I read the project wiki, wrote some working code and joined their Facebook group to ask questions around prefix lookup. The community was helpful, especially Igor and Siying who gave me enough hints around prefix lookup, using custom extractors and bloom filters which helped me write something that actually worked in our production environment for the first time. Explaining the technology and jargons is out of scope of this post but I would like to encourage the readers to read about LevelDB and to read the RocksDB wiki.
RocksDB FB Group
For capturing the URLs with peak velocity up to 10k serves/s, I reused our distributed queue based infrastructure. For storage, search and retrieval of URLs I wrote a custom datastore service using C++, RocksDB and Thrift called HarvestDB. Thrift provided the RPC mechanism for implementing this system as a distributed service accessible by various backend sub-systems. The backend sub-systems use client libraries generated by Thrift compiler for communicating with the HarvestDB server.
The HarvestDB service implements five remote procedures - ping, get, put, search and purge. The following Thrift IDL describes this service.
namespace cpp harvestdb
namespace go harvestdb
namespace py harvestdb
namespace php HarvestDB
struct Url {
1: required i64 timestamp;
2: required string url;
3: required string version;
}
typedef list<Url> UrlList
struct UrlResult {
1: required i32 prefix;
2: required i32 found;
3: required i32 total;
4: required list<string> urls;
}
service HarvestDB {
bool ping(),
Url get(1:i32 prefix, 2:string url),
bool put(1:i32 prefix, 2:Url url),
UrlResult search(1:i32 prefix,
2:string includeRegex,
3:string excludeRegex,
4:i32 size,
5:i32 timeout),
bool purge(1:i32 prefix, 2:i64 timestamp)
}Clients use ping to check HarvestDB server connectivity before executing
other procedures. RabbitMQ consumers consume collected URLs and put them to
HarvestDB. The PHP based application backend uses custom Thrift based client
library to get (read) and to search URLs.
A Python program runs as a periodic cron job and uses purge procedure to purge old entries
based on timestamp which makes sure we don't exhaust our storage
resources. The system is in production for more than five months now and is
capable of handling (benchmarked) workload of up to 24k writes/second while consuming
less than 500MB RAM. Our future work will be on replication, sharding and fault
tolerance of this service. The following diagram illustrates this architecture.
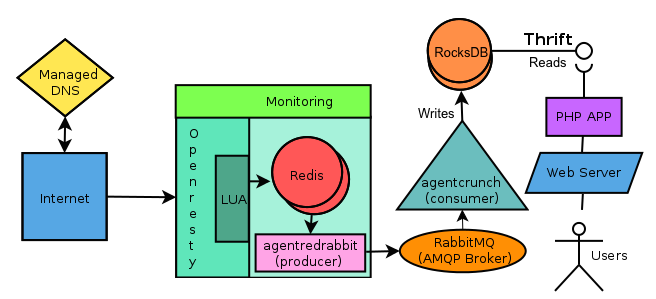
Overall architecture